
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- kt 에이블스쿨 6기 ai
- kt 에이블스쿨 6기
- 케이티 에이블스쿨 6기 후기
- KT AIVLE
- 케이티 에이블스쿨 6기 java
- 프로그래머스
- 티스토리챌린지
- ElasticSearch
- 구현
- 엘라스틱서치
- 오블완
- 케이티 에이블스쿨 기자단
- 앙상블
- 에이블 기자단
- SQLD
- 케이티 에이블스쿨 6기
- 백준
- 데이터 프레임
- kt aivle school
- 파이썬
- 케이티 에이블스쿨
- KT 에이블스쿨
- 알고리즘
- 네트워크
- kt 에이블스쿨 기자단
- kt 에이블스쿨 6기 빅프로젝트
- 판다스
- kt 에이블스쿨 6기 미니 프로젝트
- 머신러닝
- 케이티 에이블스쿨 6기 ai
Archives
- Today
- Total
미식가의 개발 일기
[머신러닝] 회사 합격 여부 예측하기(분류: 결정 트리, 랜덤 포레스트) 본문
캐글 -> Datasets -> Recruitment Data 검색 -> csv 파일 다운로드 후 실습 진행


데이터 불러온 후 확인
import pandas as pd
train = pd.read_csv('datas/recruitment_data.csv')
display(train.head()) # 앞에 5줄 보기
display(len(train)) # 데이터 개수 보기
특성과 타겟 컬럼 분리
- 회사 합격 여부를 의미하는 HiringDecision을 분리한다.
train_x = train.drop(['HiringDecision'], axis=1)
train_y = train['HiringDecision']
학습 데이터, 검증 데이터 분리
from sklearn.model_selection import train_test_split
# 학습 데이터, 검증 데이터 분리
X_train, X_valid, y_train, y_valid = train_test_split(train_x, train_y, test_size=0.2, random_state=10)
# 분리된 데이터 크기 확인
display(X_train.shape)
display(X_valid.shape)
-> 학습 데이터: 1200개, 검증 데이터: 300개로 분리
검증 데이터 제외하고 학습 및 예측
- RandomForestClassifier와 Decision Tree로 진행
# from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# model = DecisionTreeClassifier(random_state=10)
model = RandomForestClassifier(random_state=10)
model.fit(X_train, y_train)
y_predict = model.predict(X_valid)
성능 평가
- 각 성능 평가에 대한 설명은 아래 포스팅에서 확인
- https://irreplaceablehotgirl.tistory.com/17#toc3
머신러닝 분류 문제 vs 회귀 문제
예측하려는 목표 변수의 유형에 따라 분류 문제와 회귀 문제로 나뉜다. 용어 정리이산적 값구분되는 개별적인 값을 가지는 데이터, 두 값 사이에는 무한한 값이 존재하지 않는다.정수형 데이터
irreplaceablehotgirl.tistory.com
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
cf_mat = confusion_matrix(y_valid, y_predict)
accuracy_diabets_DT = accuracy_score(y_valid, y_predict)
precision_diabets_DT = precision_score(y_valid, y_predict)
recall_diabets_DT = recall_score(y_valid, y_predict)
f1_score_diabets_DT = f1_score(y_valid, y_predict)
display(f"Accuracy:{accuracy_diabets_DT}")
display(f"precision:{precision_diabets_DT}")
display(f"recall: {recall_diabets_DT}")
display(f"f1_score: {f1_score_diabets_DT}")
display(f"Confusion Matrix: {cf_mat}")
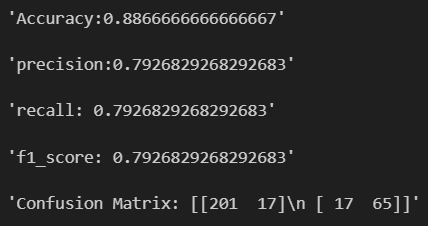
-> 전반적으로 RandomForestClassifier를 사용했을 때 성능이 더 좋다.
반응형
'ML, DL' 카테고리의 다른 글
| [머신러닝] 성적 예측하기(회귀: 선형 회귀, 랜덤 포레스트, XGBRegressor) (3) | 2024.07.15 |
|---|---|
| [머신러닝] 데이터 변환 및 시각화(with 캐글) (0) | 2024.07.14 |
| [머신러닝] 분류 문제 vs 회귀 문제 (0) | 2024.07.13 |
| [머신러닝] 로지스틱 회귀분석(Logistic Regresstion) (2) | 2024.07.13 |
| [머신러닝] 범주형 데이터 인코딩 (1) | 2024.07.12 |