
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 케이티 에이블스쿨 6기
- kt 에이블스쿨 6기 빅프로젝트
- 티스토리챌린지
- 에이블 기자단
- kt 에이블스쿨 6기 미니 프로젝트
- kt 에이블스쿨 기자단
- KT 에이블스쿨
- 판다스
- kt 에이블스쿨 6기 ai
- 앙상블
- ElasticSearch
- 엘라스틱서치
- 네트워크
- 케이티 에이블스쿨
- 케이티 에이블스쿨 6기 java
- 프로그래머스
- SQLD
- 데이터 프레임
- 케이티 에이블스쿨 6기 ai
- 머신러닝
- kt aivle school
- 구현
- 케이티 에이블스쿨 6기 후기
- kt 에이블스쿨 6기
- KT AIVLE
- 케이티 에이블스쿨 기자단
- 백준
- 파이썬
- 알고리즘
- 오블완
Archives
- Today
- Total
미식가의 개발 일기
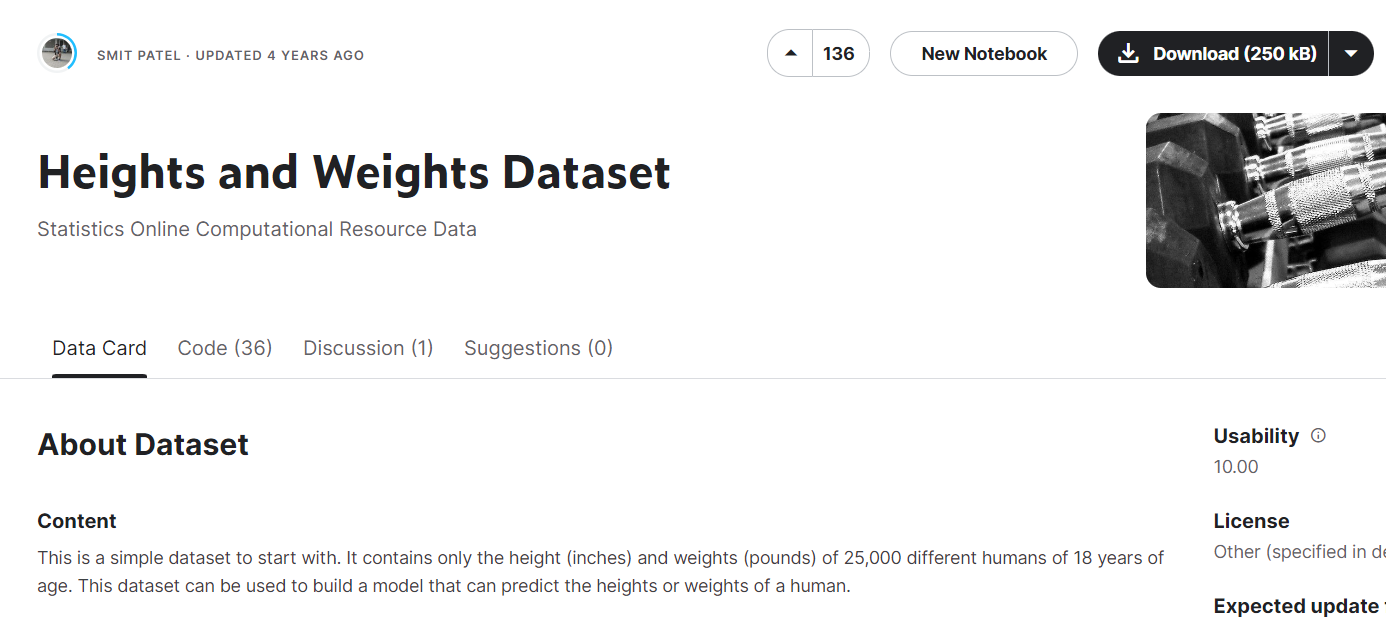
[머신러닝] 데이터 변환 및 시각화(with 캐글) 본문
캐글 -> Datasets -> Heghts and Weights 검색 -> csv 다운로드 후 실습 진행
데이터 표준화
데이터 표준화란?
- 데이터의 특성들을 평균이 0이고 분산이 1이 되도록 조정하는 작업
데이터 표준화를 왜 해야할까?
"특성 간의 단위 차이 해소를 위해서이다."
-> 각 특성이 다른 단위를 가진다면 큰 값을 가지는 특성이 더 영향을 미치게 된다. 따라서 표준화를 통해 모든 특성이 동일한 범위를 가지게 하여 균형 있는 학습을 할 수 있다.
데이터 불러오기
import pandas as pd
data = pd.read_csv("datas/HeightWeight.csv")
display(data.head())
display(len(data))
데이터 분포 확인
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['axes.unicode_minus'] = False # minus 부호 출력 설정
plt.figure(figsize=(6, 3))
# kde=True: 곡선 추가
sns.histplot(data['Height(Inches)'], kde=True, label='키', color="Skyblue")
sns.histplot(data['Weight(Pounds)'], kde=True, label='몸무게', color="Salmon")
plt.legend()
plt.show()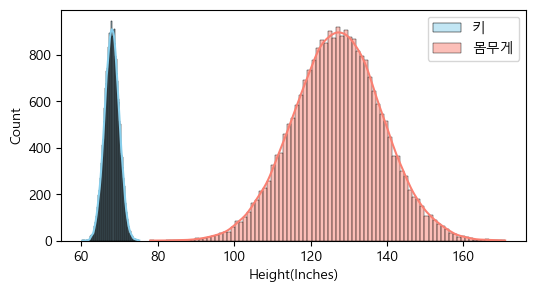
Standard Scaler
Standard Scaler 객체 생성
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
Index 컬럼은 필요 없으므로 제거
data = data.drop(['Index'], axis=1)
표준화 후 데이터 프레임으로 변환
scaler.fit(data) # 데이터의 평균과 표준편차 계산
scaler_data = scaler.transform(data) # 평균을 빼고 표준편차로 나눠 표준화
scaler_data = pd.DataFrame(scaler_data, columns=[['키', '몸무게']])
scaler_data
표준화 후 데이터 분포
- 단일 색상으로 사용할 땐 color, 범주형 변수의 색을 지정할 땐 palette로 색 지정
import matplotlib.pyplot as plt
import seaborn as sns
# Figure 객체 생성
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
sns.histplot(scaler_data['키'], kde=True, palette="Blues", ax=ax1)
ax1.set_title('키')
sns.histplot(scaler_data['몸무게'], kde=True, palette="Reds", ax=ax2)
ax2.set_title('몸무게')
plt.show()
데이터 정규화
데이터 정규화란?
- 변수를 일정한 범위로 조정하는 방법
데이터 정규화를 왜 해야할까?
"데이터 값을 조정하고 분산을 줄이기 위해서이다. "
-> 데이터 값이나 분산이 너무 크거나 작으면 모델의 학습에 부정적인 영향을 미칠 수 있다.
MinMaxScaler
- 수치형 데이터 값을 0과 1 사이의 값으로 변환

from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(data[data.columns[1:]])
data[data.columns[1:]] = scaler.transform(data[data.columns[1:]])
data.head()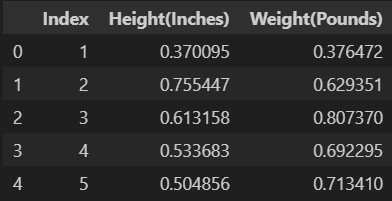
로그 변환
로그 변환이란?
- 로그 계산으로 데이터의 왜곡된 분포를 개선하는 기법이다.
로그 변환을 왜 해야할까?
"극단값의 영향을 줄이기 위해서이다."
-> 극단값이나 이상치는 분석 결과를 왜곡시킬 수 있으므로 조정이 필요하다.
원본 데이터, 로그 데이터 생성
import numpy as np
data = [1, 10, 100, 1000, 10000, 100000, 1000000, 10000000]
log_data = np.log(data)
로그 변환 전, 후 비교
import matplotlib.pyplot as plt
import seaborn as sns
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
sns.histplot(data, kde=True, color="Skyblue", ax=ax1)
ax1.set_title('로그 변환 전')
sns.histplot(log_data, kde=True, color="Salmon", ax=ax2)
ax2.set_title('로그 변환 후')
plt.show()
반응형
'ML, DL' 카테고리의 다른 글
| [머신러닝] 지도 학습, 비지도 학습, 강화 학습 (0) | 2024.07.20 |
|---|---|
| [머신러닝] 성적 예측하기(회귀: 선형 회귀, 랜덤 포레스트, XGBRegressor) (3) | 2024.07.15 |
| [머신러닝] 회사 합격 여부 예측하기(분류: 결정 트리, 랜덤 포레스트) (7) | 2024.07.14 |
| [머신러닝] 분류 문제 vs 회귀 문제 (0) | 2024.07.13 |
| [머신러닝] 로지스틱 회귀분석(Logistic Regresstion) (2) | 2024.07.13 |