
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 케이티 에이블스쿨 6기 ai
- kt aivle school
- 티스토리챌린지
- kt 에이블스쿨 6기
- 앙상블
- 오블완
- 케이티 에이블스쿨 6기 후기
- 엘라스틱서치
- 머신러닝
- kt 에이블스쿨 6기 빅프로젝트
- 프로그래머스
- kt 에이블스쿨 기자단
- 케이티 에이블스쿨 6기 java
- 케이티 에이블스쿨 기자단
- 에이블 기자단
- SQLD
- 케이티 에이블스쿨 6기
- KT AIVLE
- 알고리즘
- 네트워크
- 케이티 에이블스쿨
- 백준
- ElasticSearch
- kt 에이블스쿨 6기 ai
- kt 에이블스쿨 6기 미니 프로젝트
- 판다스
- 데이터 프레임
- 파이썬
- KT 에이블스쿨
- 구현
Archives
- Today
- Total
미식가의 개발 일기
[머신러닝] 성적 예측하기(회귀: 선형 회귀, 랜덤 포레스트, XGBRegressor) 본문
캐글 -> Datasets -> Student Performance 검색 -> csv 파일 다운로드 후 실습 진행
데이터 불러온 후 확인
import pandas as pd
data = pd.read_csv("datas/student_performance.csv")
display(data.head())
display(len(data))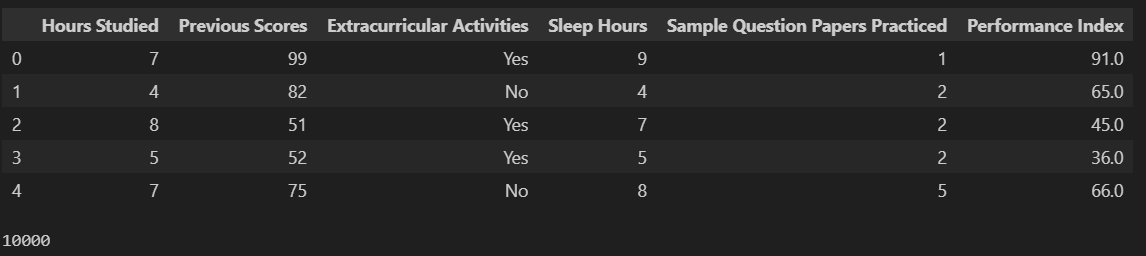
특성과 타켓 컬럼 분리
from sklearn.model_selection import train_test_split
X = data.drop(['Extracurricular Activities', 'Performance Index'], axis=1)
y = data['Performance Index']
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=20)- Extracurricular Activities는 문자열 데이터이므로 제거, Performance Index는 타켓 컬럼이므로 제거 후 y에 할당
표준화
from sklearn.preprocessing import StandardScaler
scale_data = ['Hours Studied', 'Previous Scores', 'Sleep Hours', 'Sample Question Papers Practiced']
scaler = StandardScaler()
X_train[scale_data] = scaler.fit_transform(X_train[scale_data])
X_valid[scale_data] = scaler.transform(X_valid[scale_data])- 타켓 컬럼을 제외한 모든 컬럼 표준화
선형 회귀 모델 구축
from sklearn.linear_model import LinearRegression
LR_model = LinearRegression()
LR_model.fit(X_train, y_train)
y_predict = LR_model.predict(X_valid)
- OLS 모델로 선형 회귀 구현
# OLS 모델을 사용하기 위해서는 컬럼에 공백이 있으면 에러 발생
# inplace=True는 원본 데이터를 변경한다는 뜻
data.rename(columns={
'Hours Studied': 'hours_studied',
'Previous Scores': 'previous_scores',
'Extracurricular Activities': 'extracurricular_activities',
'Sleep Hours': 'sleep_hours',
'Sample Question Papers Practiced': 'sample_question_papers_practiced',
'Performance Index': 'performance_index'
}, inplace=True)
data.head()
test_data = data.drop(['performance_index'], axis=1)
formula = """
performance_index ~ (hours_studied) + (previous_scores) + (sleep_hours) + (sample_question_papers_practiced)
"""
import statsmodels.api as sm
model = sm.OLS.from_formula(formula, data=data)
model = model.fit()
predict = model.predict(test_data)
predict.head()0 91.532244
1 63.469569
2 44.736196
3 36.241825
4 67.390699
dtype: float64
랜덤 포레스트 모델 구축
from sklearn.ensemble import RandomForestRegressor
RF_model = RandomForestRegressor()
RF_model.fit(X_train, y_train)
y_predict = RF_model.predict(X_valid)
XGBRegressor 모델 구축
from xgboost import XGBRegressor
XGB_model = XGBRegressor()
XGB_model.fit(X_train, y_train)
y_predict = XGB_model.predict(X_valid)
y_predict
성능 평가
- 성능 평가에 대한 자세한 내용은 아래 포스팅 참고
- https://irreplaceablehotgirl.tistory.com/17#toc6
머신러닝 분류 문제 vs 회귀 문제
예측하려는 목표 변수의 유형에 따라 분류 문제와 회귀 문제로 나뉜다. 용어 정리이산적 값구분되는 개별적인 값을 가지는 데이터, 두 값 사이에는 무한한 값이 존재하지 않는다.정수형 데이터
irreplaceablehotgirl.tistory.com
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error
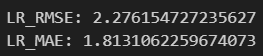
LR_rmse = np.sqrt(mean_squared_error(y_valid, y_predict))
LR_mae = mean_absolute_error(y_valid, y_predict)
print(f'LR_RMSE: {LR_rmse}')
print(f'LR_MAE: {LR_mae}')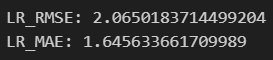
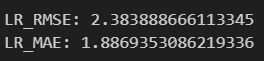
모델을 사용하여 test 데이터에 대한 예측을 수행
# test 데이터 생성 -> 특성 분리와 표준화 진행
X_test = data.drop(['Extracurricular Activities', 'Performance Index'], axis=1)
X_test[scale_data] = scaler.transform(X_test[scale_data])
# 예측
test_prediction = RF_model.predict(X_test)
- 데이터 프레임으로 실제값과 예측값 비교하기
res = pd.DataFrame({
'실제 성적': data["Performance Index"],
'예측한 성적': test_prediction
})
res.head()
반응형
'ML, DL' 카테고리의 다른 글
| [머신러닝] 정규 표현식 사용하여 데이터 변환 (2) | 2024.07.20 |
|---|---|
| [머신러닝] 지도 학습, 비지도 학습, 강화 학습 (0) | 2024.07.20 |
| [머신러닝] 데이터 변환 및 시각화(with 캐글) (0) | 2024.07.14 |
| [머신러닝] 회사 합격 여부 예측하기(분류: 결정 트리, 랜덤 포레스트) (7) | 2024.07.14 |
| [머신러닝] 분류 문제 vs 회귀 문제 (0) | 2024.07.13 |