
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 오블완
- kt 에이블스쿨 6기 미니 프로젝트
- kt 에이블스쿨 6기 ai
- 에이블 기자단
- 프로그래머스
- KT 에이블스쿨
- SQLD
- 케이티 에이블스쿨 6기 java
- 네트워크
- KT AIVLE
- 케이티 에이블스쿨 6기 후기
- kt 에이블스쿨 기자단
- ElasticSearch
- kt 에이블스쿨 6기
- 백준
- 엘라스틱서치
- 케이티 에이블스쿨
- 알고리즘
- 케이티 에이블스쿨 6기 ai
- 케이티 에이블스쿨 기자단
- 티스토리챌린지
- kt aivle school
- 구현
- 케이티 에이블스쿨 6기
- 앙상블
- 데이터 프레임
- 머신러닝
- kt 에이블스쿨 6기 빅프로젝트
- 판다스
- 파이썬
- Today
- Total
미식가의 개발 일기
[Elasticsearch] 엘라스틱서치 인덱싱 본문
엘라스틱서치에서 인덱스란?
데이터를 저장하는 공간으로 매핑을 통해 데이터 구조를 정의할 수 있다.
📖 인덱스 생성 구조
- 해당 API로 PUT 요청을 보내면 새로운 인덱스가 생성된다.
PUT : https://ip:9200/index_name
- 인덱스 생성을 위해서는 JSON body에 2가지를 정의해야 한다.
- `settings`: 클러스터, 인덱스 운영 설정(샤드 개수, 복제본 수, 텍스트 분석기 정의(커스텀 필터 등록) 등)
- `mappings`: 필드 이름과 데이터 타입 지정
해당 예제는 커스텀 analyzer인 `my_analyzer`에 `standard` tokenizer로 모든 단어를 분리하고, `lowercase` filter를 적용해 모든 단어를 소문자로 변환하도록 지정한다.
`title`과 `content` 필드에 해당 커스텀 analyzer를 적용하고, id는 검색에 사용하지 않도록 `index: false`로 정의되었다.
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "standard",
"filter": ["lowercase"]
}
},
"char_filter": {
},
"tokenizer": {
"standard": {
"type": "standard"
}
},
"filter": {
"lowercase": {
"type": "lowercase"
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "long",
"index": false
},
"title": {
"type": "text",
"analyzer": "my_analyzer"
},
"content": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
※ elastic 공식 인덱스 생성 가이드
analyzer | Reference
The analyzer parameter specifies the analyzer used for text analysis when indexing or searching a text field. Unless overridden with the search_analyzer...
www.elastic.co
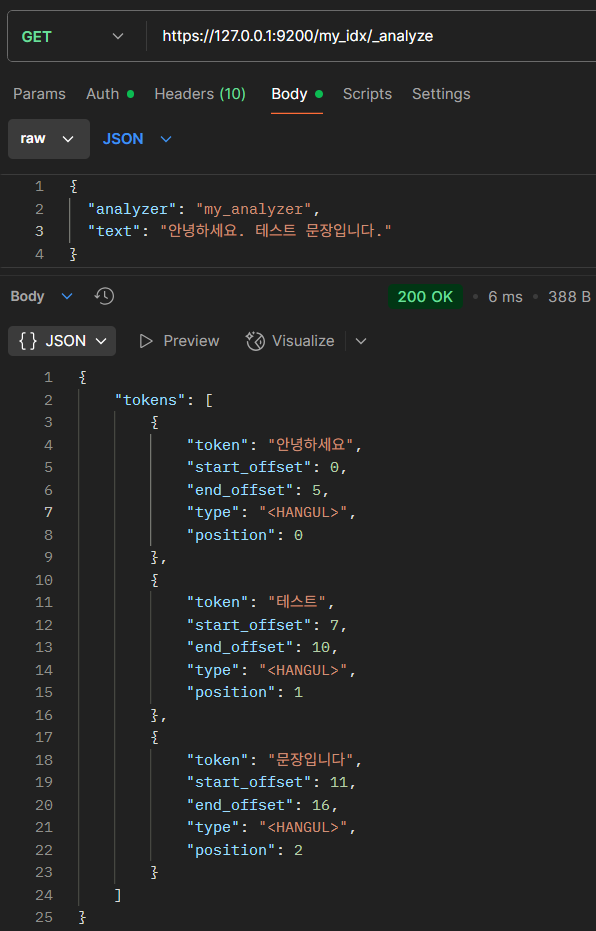
분석기 테스트
GET : https://ip:9200/index_name/_analyze
{
"analyzer": "my_analyzer",
"text": "안녕하세요. 테스트 문장입니다."
}
📖 nori tokenizer
앞서 사용한 standard tokenizer는 단순 띄어쓰기 및 문장 부호 기준 토큰화를 진행하므로 한글의 조사나 어미를 잘 처리하지 못한다.
따라서 한글을 처리할 때는 nori tokenizer를 주로 사용한다.
1. 엘라스틱서치 컨테이너 접속
sudo docker exec -it es /bin/bash
2. nori 분석기 설치
bin/elasticsearch-plugin install analysis-nori
3. 엘라스틱서치 컨테이너 재시작
sudo docker restart es
4. setting에 nori tokenizer 추가
- `decompound_mode`: 복합어 분해 방법
- `none`: 분해 X
- `discard`: 분해해서 버림
- `mixed`: 분해해서 포함 (복합어 + 원어)
- `discard_punctuation`: 문장 부호를 제거할지 여부 (`true`, `false`)
- `lenient`: 오류에 관대하게 동작할지 여부 (`true`, `false`)
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "nori",
"filter": ["lowercase"]
}
},
"char_filter": {
},
"tokenizer": {
"nori": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": true,
"ienient": true
}
},
"filter": {
"lowercase": {
"type": "lowercase"
}
}
}
}📖 사용자 사전 기반 tokenizer
특정 단어들만 커스텀하여 분해하고 싶다면 사용자 사전을 사용하면 된다.
1. 컨테이너 외부에 userdict.txt 생성
- 컨테이너 내부에 두면 임사 파일로 처리되며 유지, 접근이 어렵다.

mkdir elastic_dict
cd elastic_dict
touch userdict.txt
2. 기존 컨테이너 제거 후 새로 생성
- 제거
sudo docker stop es
sudo docker rm es
- 재생성
sudo docker run -d --restart unless-stopped \
--name es \
-v /home/mingd/elastic_dict/:/usr/share/elasticsearch/config/dict/ \ # 여기에 경로 추가
-p 9200:9200 -p 9300:9300 \
--network myes \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms2g -Xmx2g" \
docker.elastic.co/elasticsearch/elasticsearch:8.17.2
- 비밀번호 재설정
sudo docker exec -it es /bin/bash
bin/elasticsearch-setup-passwords interactive
- nori 분석기 재설치
bin/elasticsearch-plugin install analysis-nori
sudo docker restart es
3. settings 수정
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "nori",
"filter": ["lowercase"]
}
},
"char_filter": {
},
"tokenizer": {
"nori": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": true,
"ienient": true,
"user_dictionary": "dict/userdict.txt" # 여기에 경로 추가
}
},
"filter": {
"lowercase": {
"type": "lowercase"
}
}
}
}
4. userdict.txt 작성
- txt 파일 수정 후에는 컨테이너 재시작 필수

📖 동의어 사전 기반 filter
문장 분해가 끝나면 filtering 작업을 해주는데 동의어 사전을 만들어 특정 단어를 치환, 확장한다.
⚠️ 주의사항 (tokenizer와 synonym filter 충돌)
- 동의어 필터는 tokenizer 이후에 적용된다.
- 따라서, 동의어 사전에 정의된 단어들이 tokenizer에서 정확히 분리되는 단위와 일치해야 한다.
- 예를 들어:
- tokenizer가 "운동화"를 "운동", "화"로 나눈다면,
동의어 사전에서 "운동화 => 스니커즈"로 지정해도 작동하지 않음. - 이 경우 "운동화"가 하나의 token으로 유지되도록 사용자 사전에 등록해야 동의어 필터가 적용 가능.
- tokenizer가 "운동화"를 "운동", "화"로 나눈다면,
✅ 따라서 동의어로 처리할 단어는 tokenizer에서 분리되지 않도록 사용자 사전에 미리 정의해두어야 한다.
1. 컨테이너 외부에 userdict.txt 생성
※ 위에서 폴더 만들고 마운트 했으므로 엘라스틱 컨테이너 재성성하지 않아도 됨
cd elastic_dict
touch synonym.txt
2. settings 수정
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "nori",
"filter": ["lowercase", "synonym"] # 여기에 추가
}
},
"char_filter": {},
"tokenizer": {
"nori": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": true,
"ienient": true,
"user_dictionary": "dict/userdict.txt"
}
},
"filter": {
"lowercase": {
"type": "lowercase"
},
# 여기에 추가
"synonym": {
"type": "synonym",
"synonyms_path": "dict/synonym.txt",
"lenient": true
}
}
}
}
3. synonym.txt 작성
- txt 파일 수정 후에는 컨테이너 재시작 필수
확장
ai, 인공지능, artificial intelligence
택배, 배송, 배달
휴대폰, 스마트폰, 모바일
치환
이메일 => 메일
핸드폰 => 휴대폰
노트북컴퓨터 => 노트북
택배를 검색하면 type이 synonym인 배송, 배달이 함께 검색되고, 이메일 > 메일로 검색되는 것을 확인할 수 있다.

'Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] Elasticsearch 검색 API (1) | 2025.07.13 |
|---|---|
| [Elasticsearch] Bulk API: Elasticsearch 대량 색인 작업 (0) | 2025.07.13 |
| [Elasticsearch] 엘라스틱서치, 키바나 설치하기: Ubuntu(WSL), Docker 환경 (1) | 2025.07.06 |
| [Elasticsearch] 엘라스틱서치란? (2) | 2025.07.05 |