
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 구현
- kt 에이블스쿨 6기
- 알고리즘
- SQLD
- 케이티 에이블스쿨 6기 java
- 머신러닝
- kt 에이블스쿨 기자단
- kt aivle school
- 케이티 에이블스쿨 6기 후기
- 오블완
- ElasticSearch
- 데이터 프레임
- 앙상블
- 케이티 에이블스쿨
- 프로그래머스
- 케이티 에이블스쿨 6기 ai
- 판다스
- KT 에이블스쿨
- 케이티 에이블스쿨 6기
- 백준
- kt 에이블스쿨 6기 미니 프로젝트
- kt 에이블스쿨 6기 빅프로젝트
- 네트워크
- 엘라스틱서치
- 에이블 기자단
- 케이티 에이블스쿨 기자단
- 티스토리챌린지
- 파이썬
- KT AIVLE
- kt 에이블스쿨 6기 ai
- Today
- Total
미식가의 개발 일기
[Elasticsearch] 엘라스틱서치란? 본문
1️⃣ 엘라스틱서치란?
대용량의 데이터를 실시간으로 검색하고 분석할 수 있도록 설계된 분산형 오픈소스 검색엔진이다.
구조화된 데이터뿐만 아니라 비정형 텍스트, 로그, 메트릭, 문서 등 다양한 형태의 데이터를 빠르게 처리할 수 있다.
💡 검색엔진
사용자가 입력한 검색어(쿼리)를 바탕으로, 방대한 데이터 중에서 관련된 정보를 빠르게 찾아주는 소프트웨어 시스템이다.
웹사이트, 문서, 상품, 로그 등 다양한 데이터 유형에 적용되며, 오늘날 거의 모든 온라인 서비스의 핵심 기술로 자리 잡고 있다.
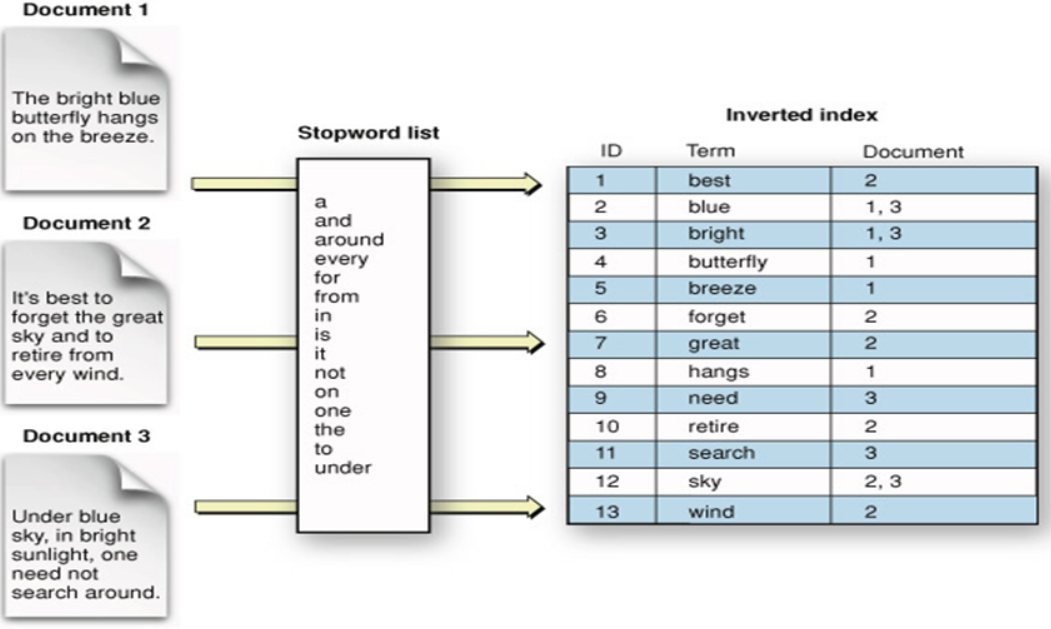
💡 엘라스틱서치 인덱싱 과정
JSON 형태의 문서 → 역색인(Inverted Index) 생성 → 토큰화 및 분석 → 문서를 인덱스에 저장
단순한 key-value 저장소가 아닌 역색인 구조를 사용하기에 수백만 개 문서도 빠르게 검색할 수 있다.
- 일반 인덱스: 문서 → 단어
- 역색인: 단어 → 문서 목록
💡 엘라스틱서치 문장 분석 과정
- char_filter > tokenizer > token_filter 과정을 거친다.
[문장]
↓ 1. char_filter (문자 치환: html 태그 제거, 특수문자 치환)
[전처리된 문장]
↓ 2. tokenizer (단어 분리) * 한국어는 거의 NORI tokenizer 사용 *
[토큰 목록]
↓ 3. token_filter (불필요한 토큰 제거 및 변환: 소문자 변환, 어간 추출 등)
[최종 토큰 목록] → 인덱싱💡 엘라스틱서치 구성 요소
| 구성 요소 | 설명 |
| Cluster | 노드의 집합 |
| Node | Elasticsearch 실행 단위 |
| Index | 문서 저장 논리 단위 |
| Shard | 인덱스를 나눈 조각 (물리적 단위) |
| Document | 실제 저장되는 데이터 (JSON) |

2️⃣ 엘라스틱서치 특징
💡 FTS: Full-Text Search
문서 전체 내용을 대상으로 단어(키워드)를 검색하는 방식이다.
단순한 `WHERE title = '엘라스틱서치' `같은 값 일치 검색이 아니라, 자연어 문장을 쪼개고 분석해서 "의미 있는 단어가 포함되어 있는지"를 검색하는 방식이다.
RDB에에서도 FTS는 가능하지만 실무에서 사용하기에는 여러 한계가 존재하며 엘라스틱서치의 강력한 커스터마이징 기능을 따라가기 어렵다.
💡 RESTful API 기반
엘라스틱서치는 HTTP를 통해 JSON 형식의 RESTful API를 이용하며, 손쉽게 데이터를 CRUD(Create, Read, Update, Delete) 할 수 있다. 덕분에 다양한 언어와 플랫폼에서 접근이 용이하다.
💡 거의 실시간 검색
데이터를 저장한 직후 거의 실시간(NRT, Near Real-Time)으로 검색할 수 있다.
1초 미만 ~ 수 초 수준의 지연이 있다.
💡 분산 아키텍처
클러스터 기반으로 작동하며, 데이터를 샤드 단위로 분산 저장한다.
각 샤드는 레플리카(샤드의 복사본)를 가질 수 있어 데이터의 안정성과 수평 확장성을 동시에 확보할 수 있다.
💡 스키마리스 구조
처음에는 명시적인 스키마가 없으며 필드 유형을 자동으로 추론해준다. 필요한 경우 명시적인 매핑 설정도 가능하다.
💡 다양한 통계 및 집계 가능
단순 검색을 넘어 데이터를 집계하여 통계, 차트, 대시보드로 활용할 수 있다.
※ 시간대별 요청 수, 평균 최대 최소 값 계산, 조건별 그룹
3️⃣ 엘라스틱서치 vs 관계형 데이터베이스
| Elasticsearch | 관계형 데이터베이스 |
| 인덱스 | 데이터베이스 |
| 샤드 | 파티션 |
| 타입 | 테이블 |
| 문서 | 행 |
| 필드 | 열 |
| 매핑 | 스키마 |
| Query DSL | SQL |
💡 추가, 검색, 삭제, 수정 기능 비교
| 엘라스틱서치에서의 HTTP 메서드 | 기능 | 데이터베이스 질의 문법 |
| GET | 데이터 조회 | SELECT |
| PUT | 데이터 생성 | INSERT |
| POST | 인덱스 업데이트, 데이터 조회 | UPDATE, SELECT |
| DELETE | 데이터 삭제 | DELETE |
| HEAD | 인덱스의 정보 확인 | - |
4️⃣ 엘라스틱서치 사용 사례
- 로그 분석: ELK 스택 (Elasticsearch + Logstash + Kibana)
- 검색 서비스: 쇼핑몰, 뉴스 사이트의 텍스트 검색
- 추천 시스템: 유사 콘텐츠 검색
- 모니터링: APM(Application Performance Monitoring), 실시간 지표 수집 및 시각화
- RAG 시스템의 백엔드 검색엔진 (최근엔 dense_vector도 지원)
5️⃣ 엘라스틱서치 장점
- 강력한 커스텀 기능: 토크나이징을 통해 검색 커스텀을 다양하게 할 수 있다. (인덱싱을 잘 한다면 검색어 자동 소문자 처리, 조사 처리, 합성어 처리 등 다양한 검색어를 처리할 수 있음)
6️⃣ 엘라스틱서치 한계점
- 실시간 검색 X, 벡터 검색 한계, 리소스 소비 큼, 설정이 복잡.
'Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] Elasticsearch 검색 API (1) | 2025.07.13 |
|---|---|
| [Elasticsearch] Bulk API: Elasticsearch 대량 색인 작업 (0) | 2025.07.13 |
| [Elasticsearch] 엘라스틱서치 인덱싱 (1) | 2025.07.06 |
| [Elasticsearch] 엘라스틱서치, 키바나 설치하기: Ubuntu(WSL), Docker 환경 (1) | 2025.07.06 |