
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- KT 에이블스쿨
- kt aivle school
- 에이블 기자단
- kt 에이블스쿨 6기 ai
- 네트워크
- 알고리즘
- kt 에이블스쿨 6기
- SQLD
- 케이티 에이블스쿨 6기 ai
- 데이터 프레임
- KT AIVLE
- 오블완
- 프로그래머스
- 케이티 에이블스쿨 기자단
- kt 에이블스쿨 6기 빅프로젝트
- 머신러닝
- 판다스
- ElasticSearch
- 구현
- 케이티 에이블스쿨 6기 후기
- 백준
- kt 에이블스쿨 기자단
- kt 에이블스쿨 6기 미니 프로젝트
- 엘라스틱서치
- 케이티 에이블스쿨 6기
- 티스토리챌린지
- 케이티 에이블스쿨
- 케이티 에이블스쿨 6기 java
- 앙상블
- 파이썬
Archives
- Today
- Total
미식가의 개발 일기
판다스란? (Series, DataFrame) 본문
판다스란?
- 데이터 조작과 분석을 위한 파이썬 라이브러리
- 표 형태의 데이터를 다루는데 매우 효과적
- 2가지 데이터 구조를 제공(데이터 프레임, 시리즈)
import pandas as pd시리즈(Series)
데이터 프레임의 한 열을 나타내는 자료구조
- 리스트로 생성
data = [10, 20, 30, 40, 50]
series = pd.Series(data)
print(series)
print(type(series))0 10
1 20
2 30
3 40
4 50
dtype: int64
<class 'pandas.core.series.Series'>- 배열로 생성
import numpy as np
data = [10, 20, 30, 40, 50]
np_data = np.array(data)
print('배열의 타입:', type(np_data))
series = pd.Series(np_data)
print(series)배열의 타입: <class 'numpy.ndarray'>
0 10
1 20
2 30
3 40
4 50
dtype: int32- 딕셔너리로 생성
data_dict = {
'a': 10,
'b': 20,
'c': 30,
'd': 40,
'e': 50
}
series = pd.Series(data_dict)
seriesa 10
b 20
c 30
d 40
e 50
dtype: int64- 시리즈에 인덱스, 이름, 데이터 타입 정해주기
data = [1, 2, 3, 4]
index = ['a', 'b', 'c', 'd']
series = pd.Series(data, index=index, name='MySeries', dtype='float')
seriesa 1
b 2
c 3
d 4
Name: MySeries, dtype: int32
데이터 프레임(DataFrame)
여러 행과 열로 구성

- 리스트로 생성
columns = ['이름', '취미']
data = [['강민지', '춤'],
['강코비', '잠자기']]
df = pd.DataFrame(data, columns=columns)
df- 딕셔너리로 생성
data = {
'이름': ['강민지', '강코비'],
'취미': ['춤', '잠자기']
}
df = pd.DataFrame(data_dict)
df- 시리즈로 생성
num = pd.Series([1, 2, 3], name='values')
df = pd.DataFrame(s)
df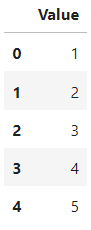
- concat() 함수를 활용해 시리즈 합치기
names = pd.Series(['강민지', '강코비'], name='name')
hobbies = pd.Series(['춤', '잠자기'], name='hobby')
df = pd.concat([names, hobbies], axis=1)
df
-> 같은 방법으로 리스트 안에 데이터 프레임을 넣으면 데이터 프레임과 시리즈도 병합 가능
반응형
'BigData' 카테고리의 다른 글
| 데이터 시각화(matplotlib, seaborn) (1) | 2024.07.19 |
|---|---|
| [판다스] 피벗 테이블 (1) | 2024.07.12 |
| [판다스] 데이터 프레임(DataFrame) 결합 (1) | 2024.07.12 |
| [판다스] 데이터 프레임(DataFrame) 조작 (1) | 2024.07.12 |
| [판다스] 시리즈(Series) 조작 (1) | 2024.07.12 |