
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 티스토리챌린지
- 백준
- 케이티 에이블스쿨 6기 ai
- 케이티 에이블스쿨
- 케이티 에이블스쿨 기자단
- ElasticSearch
- 파이썬
- 구현
- 오블완
- 앙상블
- 알고리즘
- kt 에이블스쿨 6기 미니 프로젝트
- kt 에이블스쿨 6기
- 케이티 에이블스쿨 6기 후기
- 머신러닝
- KT AIVLE
- 데이터 프레임
- 엘라스틱서치
- 네트워크
- KT 에이블스쿨
- 프로그래머스
- 판다스
- SQLD
- kt 에이블스쿨 6기 빅프로젝트
- kt aivle school
- 에이블 기자단
- 케이티 에이블스쿨 6기
- kt 에이블스쿨 기자단
- kt 에이블스쿨 6기 ai
- 케이티 에이블스쿨 6기 java
- Today
- Total
미식가의 개발 일기
데이터 시각화(matplotlib, seaborn) 본문
캐글 -> Datasets -> Amazon Stock csv 파일 다운로드 후 실습 진행

데이터 불러오기
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
data = pd.read_csv('datas/amazon_stock.csv')
display(data.head())
display(len(data))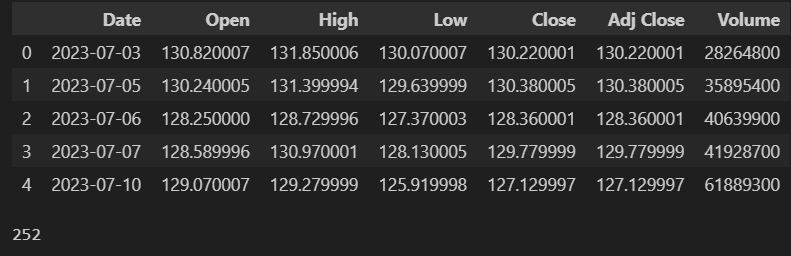
minus 부호 출력 설정
# minus 부호 출력 설정
plt.rcParams['axes.unicode_minus'] = False
막대 그래프
- 카테고리형 데이터(불연속적(=이산적) 데이터)의 값을 비교할 때 사용
- x축: 개별 범주, y축 : 해당 범주의 값
- 각 날짜의 거래량을 시각화
target_data = data[:10]
# hue: 특정 열 값에 따라 색상을 다르게 설정
sns.barplot(x=target_data['Date'], y=target_data['Volume'], hue=target_data['Date'], palette='muted')
plt.xlabel('거래 날짜')
plt.ylabel('거래량')
plt.xticks(rotation=45)
plt.show()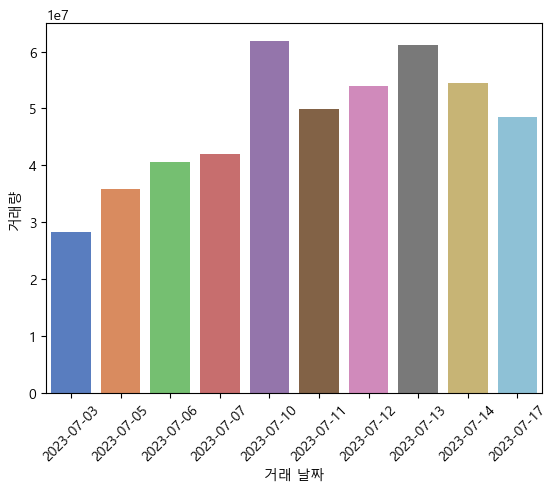
<seaborn 라이브러리 palette 종류>출처: https://seaborn.pydata.org/tutorial/color_palettes.html

히스토그램
- 연속형 데이터의 분포를 시각화 하기 위해 사용
- x축: 연속형 데이터, y축: 빈도
-> 막대가 떨어져 있으면 막대그래프, 붙어 있으면 히스토그램
x축 기준
- 'Open'열의 구간에 따른 빈도
# kde=True -> 곡선 표현하기
sns.histplot(x = data['Open'], kde=True, color='Skyblue')
plt.show()
- 수직 영역 강조
plt.figure(figsize=(6, 3))
sns.displot(data['Open'], color='Skyblue')
# alpha: 색상의 투명도를 조절(0: 투명, 1: 불투명)
plt.axvspan(xmin=160, xmax=180, alpha=0.3, color='red')
plt.show()
-> histplot: axis-level(단순), displot: figure-level(복잡, 다양)
y축 기준
sns.histplot(y = data['Open'], color='Salmon')
# 그리드 추가하기
plt.grid(True)
plt.show()
countplot
- 집계 + barplot
sns.countplot(x=data['Date'][:7], palette='Set3')
plt.title('카테고리별 데이터 개수')
plt.xlabel('카테고리')
plt.ylabel('개수')
plt.show()
선 그래프
- Date 값을 그래프에 표현 해주기 위해 Date 타입으로 변경
data['Date'] = pd.to_datetime(data['Date'])
- 그래프 그리기
# Figure 객체 생성(가로 6, 높이 3)
plt.figure(figsize=(6, 3))
sns.lineplot(x=data['Date'], y=data['Low'], label='저가', color='Skyblue')
sns.lineplot(x=data['Date'], y=data['High'], label='고가', color='Salmon')
# 라벨 수정
plt.xlabel('날짜')
plt.ylabel('주가')
# 제목 지정
plt.title('날짜별 주가 변동')
plt.show()
2개의 그래프 한번에 표현하기
# Figure 객체 생성(가로 12, 높이 6인 그림 안에 두 개의 열로 배치된 서브플롯 생성)
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
# ax1 생성
sns.lineplot(x=data['Date'], y=data['Low'], label='저가', color='Skyblue', ax=ax1)
sns.lineplot(x=data['Date'], y=data['High'], label='고가', color='Salmon', ax=ax1)
ax1.set_title('날짜별 주가 변동')
ax1.set_xlabel('날짜')
ax1.set_ylabel('주가')
# ax2 생성
sns.lineplot(x=data['Date'], y=data['Volume'], label='거래량', color='Lightgreen', ax=ax2)
ax2.set_title('날짜별 거래량')
ax2.set_xlabel('날짜')
ax2.set_ylabel('거래량')
plt.show()
산점도
- 회귀선이 포함된 산점도 -> 컬럼 간의 관계를 보여줌
sns.regplot(x = data['Close'], y = data['Volume'], line_kws = {'color': 'red'})
plt.show()
상관관계
- 수치형 데이터만 추출
numeric_data = data.select_dtypes(include=['number'])
numeric_data.head()
- 상관관계 보기
numeric_data.corr()
- 바로 수치형 데이터의 상관관계 보기
data.corr(numeric_only=True)
- 상관관계 그리기
# 이미지 크기 지정
plt.figure(figsize=(8, 4))
# annot=True -> 각 셀의 수치 표기 O
# fmt -> 소수점 지정
# cmap -> 색 지정
# vmin, vmax -> 최소, 최대 지정
ax = sns.heatmap(numeric_data.corr(), annot=True, fmt='.2f', cmap='coolwarm')
plt.show()
- 대각선 아래만 표시하려면?
mask = np.triu(np.ones_like(numeric_data.corr(), dtype=bool))
ax = sns.heatmap(numeric_data.corr(), annot=True, fmt='.2f', cmap='coolwarm', mask=mask)
sns.heatmap 관련 공식 문서
seaborn.heatmap — seaborn 0.13.2 documentation
seaborn.heatmap seaborn.heatmap(data, *, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabe
seaborn.pydata.org
상자 그림
데이터의 분포를 시각화 하는데 사용(중앙값, 이상치, IQR)
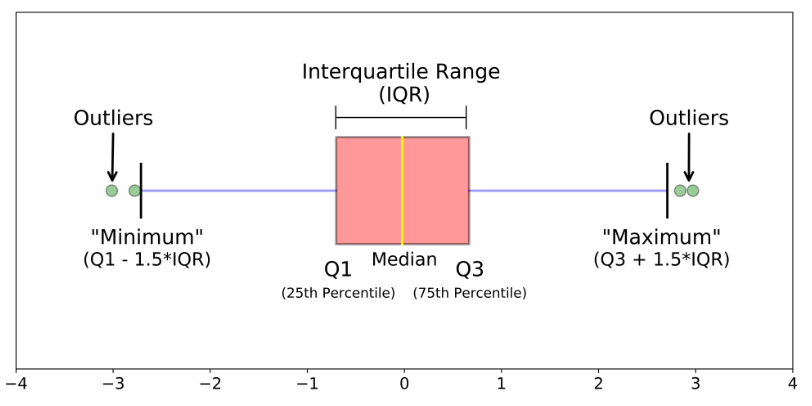
- IQR에 대해서는 아래의 포스팅을 참고해 주세요.
[머신러닝] 이상치 탐지
이상치란?"일반적인 분포에서 크게 벗어나는 데이터" 캐글 -> DataSets -> Employee Salaries Analysis csv 파일 다운로드 후 실습 진행 단변량 이상치 하나의 특징이 기준이 된다.1. Z-Score정의표준 편차를 이
irreplaceablehotgirl.tistory.com
- 상자 그림 그리기
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
#vert=False: 수평, vert=True: 수직
ax1.boxplot(data['Close'], vert=True)
ax1.set_title('종료 가격')
ax2.boxplot(data['Volume'], vert=True)
ax2.set_title('거래량')
'BigData' 카테고리의 다른 글
| [판다스] 데이터 타입 변경 (0) | 2024.08.20 |
|---|---|
| [판다스] 년도-월-일 형태 분할 후 요일 추출하기 (0) | 2024.07.23 |
| [판다스] 피벗 테이블 (1) | 2024.07.12 |
| [판다스] 데이터 프레임(DataFrame) 결합 (1) | 2024.07.12 |
| [판다스] 데이터 프레임(DataFrame) 조작 (1) | 2024.07.12 |
