
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 케이티 에이블스쿨 6기 ai
- 케이티 에이블스쿨 6기 후기
- 티스토리챌린지
- kt 에이블스쿨 6기 미니 프로젝트
- 케이티 에이블스쿨
- kt 에이블스쿨 6기
- kt 에이블스쿨 기자단
- 케이티 에이블스쿨 6기 java
- 백준
- 앙상블
- 백준 사탕 게임
- 데이터 프레임
- 판다스
- KT 에이블스쿨
- 프로그래머스
- 머신러닝
- 알고리즘
- 네트워크
- KT AIVLE
- 케이티 에이블스쿨 6기
- 파이썬
- 오블완
- kt 에이블스쿨 6기 빅프로젝트
- 에이블 기자단
- 구현
- 케이티 에이블스쿨 기자단
- kt aivle school
- 케이티 에이블스쿨 6기 spring
- kt 에이블스쿨 6기 ai
- SQLD
Archives
- Today
- Total
미식가의 개발 일기
[KT 에이블스쿨(6기, AI)] 1주차, 파이썬 기초와 Numpy & Pandas 본문

< 1주차 후기>
- 1주차는 파이썬 기초에 대해 학습했습니다!
- 대망의 첫 수업.. 기대도 많이 하고, 긴장도 많이 했는데 파이썬과 Numpy, Pandas는 그래도 한 번 사용해 봤던 거여서 수업 참여에 어려움은 없었습니다. 😊
- 데이터 분석을 위한 문법 위주로 중요한 부분만 쏙쏙 뽑아서 설명해 주신 게 좋았어요! 중요한 부분은 몇 번 반복해서 말씀해 주시고, 비교적 덜 중요한 부분은 깊게 들어가지 않고 이것만 알고 넘어가면 된다고 해주셔서 방향을 명확히 잡을 수 있었습니다.
- 이번 1주차는 알고있던 내용을 정리하고, 거기서 더 중요한 부분을 리마인드 하는 시간이였습니다. 강사님만의 노하우나 실무 경험을 공유해주시면서 이런 부분을 신경쓰면 좋다는 꿀팁도 유용했습니다. 😁
Python 기초
- Python의 자료형 중 리스트, 딕셔너리, 튜플에 대해 학습하고 조건문과 반복문, 함수를 배웠습니다.
자료형
리스트(List)
순서가 있는 변경 가능한 데이터 구조
- 생성, 수정, 삭제
# 생성
l = [1, 2, 3, 4, 5]
l = [range(1, 6, 1)] # range(시작, 끝+1, 증감)
l2 = [l, 6, 7] # 리스트 안에 리스트 포함 가능. l2 = [[1, 2, 3, 4, 5], 6, 7]
# 추가
l.append(7) # [1, 2, 3, 4, 5, 7]
# 변경
l[2] = 6 # [1, 2, 6, 4, 5, 7]
# 인덱스로 삭제
del l[2] # [1, 2, 4, 5, 7]
# 값으로 삭제
l.remove(4) # [1, 2, 5, 7]
- 조회
# 인덱싱(0부터 시작)
print(l[0], l[-1]) # 1 5
# 슬라이싱
print(l[0:3], l[:3]) # [1, 2, 3] [1, 2, 3]
딕셔너리(Dictionary)
- 키(key)와 값(value) 쌍으로 이루어진 변경 가능한 데이터 구조
- 키(key)는 중복 불가능, 값(value)은 중복 가능
- 생성, 수정, 삭제
# 생성
d = { 'k1' : 1,
'k2' : [10, 20, 30],
'k3' : {'a' : 1, 'b' : 2} }
# 추가
d['k4'] = 'coffee'
# 변경
d['k3'] = 0
# 삭제
del d['k4']
- 조회
# key로 value를 조회
d['k2'] # [10, 20, 30]
d['k2'][1] # [20]
튜플(Tuple)
소괄호로 생성하고, 변경 불가능하다는 것을 제외하면 리스트와 같습니다.
조건문
if 조건문1:
코드1
elif 조건문2:
코드2
else:
코드3
조건문1을 만족하면 코드1 실행, 조건문1을 만족하지 않고 조건문2를 만족하면 코드2 실행, 둘 다 아니면 코드3 실행
반복문
- break: 반복문 종료
- continue: 현재 반복을 멈추고 다음 반복으로 즉시 이동
for loop
# 1부터 10까지 자연수 더하기
sum = 0
for i in range(1, 11):
sum += i
print(sum)
while loop
- for loop와 달리 종료 조건을 지정해줘야 한다.
# 1부터 10까지 자연수 더하기
sum, i = 0, 1
while i <= 10: # i가 10이하일 때만 반복
sum += i
i += 1
print(sum)
함수
코드의 재사용성, 구조화, 가독성을 높이기 위해 사용
- 입력 매개변수가 2개일 때
def add(a, b):
return a + b
print(add(1, 2)) # 3
print(add(3, 5)) # 8- 입력 매개변수가 0개일 때
def greet():
return 'Hello, World'
print(greet()) # Hello, World
- 가변 인자를 받을 때
def num(*n):
print(n)
num([1, 2, 3]) # [1, 2, 3]
Numpy
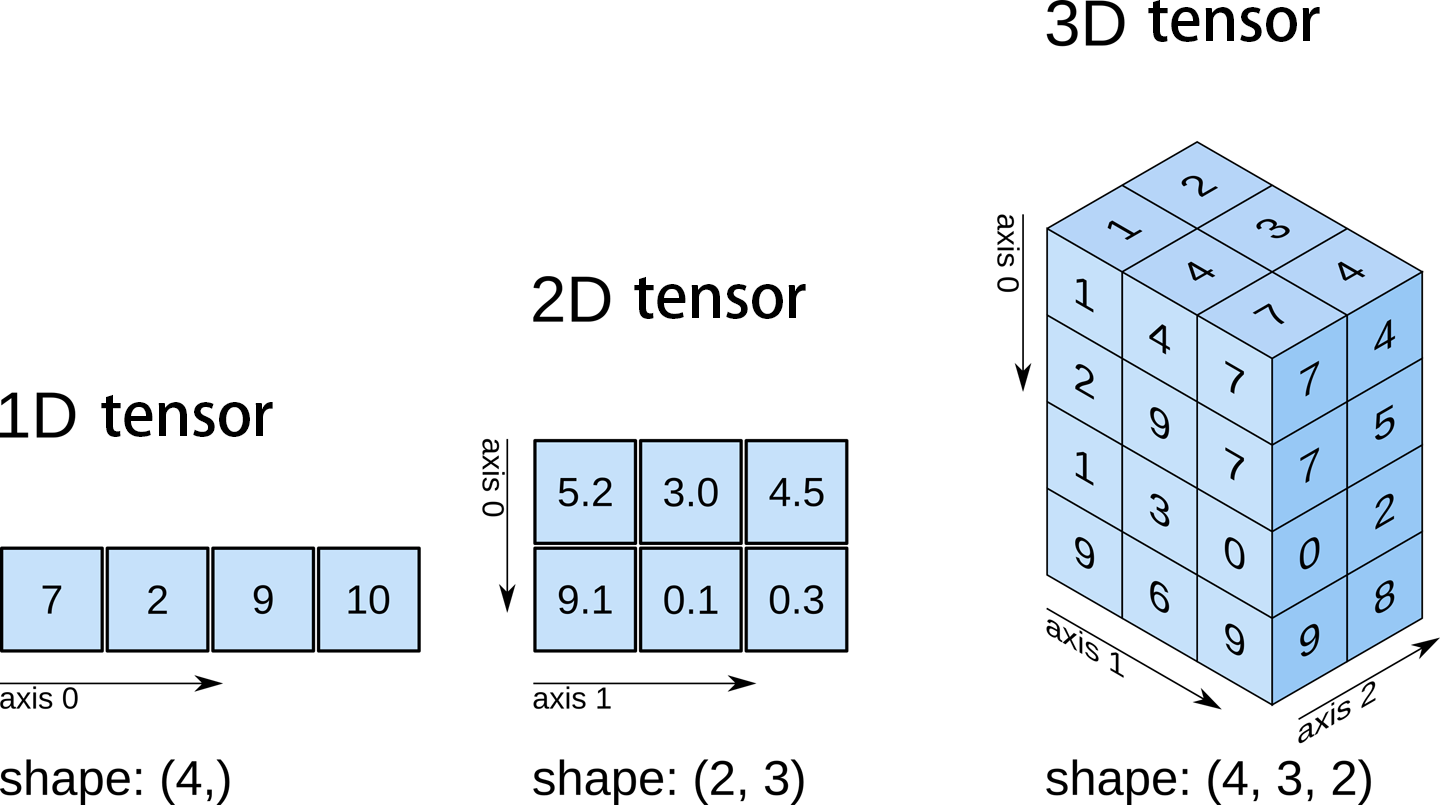
Numpy 배열
여러 차원으로 표현할 수 있으며 axis는 배열의 각 차원을 나타내는 인덱스를 의미합니다.
그 중 가장 많이 사용하는 2차원 배열의 axis는
axis=0: 세로축을 의미하며 각 열에 대한 연산을 수행
axis=1: 가로축을 의미하며 각 행에 대한 연산을 수행
라이브러리 호출
import numpy as np
2차원 배열 생성
l = [[1, 2, 3],
[4, 5, 6]]
# 배열로 변환
l = np.array(l)
배열 정보 확인
- 차원 확인: `l.dim`
- 크기(형태) 확인: `l.shape`
- 크기(형태) 변경: `l.reshape(3, 2)` ※ 전체 요소 개수는 맞춰줘야 함
- 자료형 확인: `l.dtype`
인덱싱
# 첫 번째 행 세 번째 요소
print(l[0, 2])
# 첫 번째, 두 번째 행의 첫 번째 열
print(l[[0, 2], 0])
# 첫 번째, 두 번째 열
print(l[:, [0, 1]])
슬라이싱
첫 번째 ~ 세 번째 행과 마지막 2개의 열
print(a[:3, -2:])
배열 연산
- 집계: `np.sum(l, axis=0)` `np.sum(l, axis=1)`
- 최댓값의 인덱스: `np.argmax(l)` `np.argmax(l , axis=0)` `np.argmax(l , axis=1)`
- 조건 필터: `np.where(조건, True일 때 출력할 값, False일 때 출력할 값)`
Pandas
- 데이터 조작과 분석을 위한 파이썬 라이브러리
import pandas as pd
시리즈(Series)
데이터 프레임의 한 열을 나타내는 1차원 자료구조
데이터 프레임(DataFrame)
여러 행과 열로 구성된 테이블 형태의 2차원 자료구조
생성
- 직접 생성
# 딕셔너리 만들기
d = {'Name': ['n1', 'n2', 'n3'],
'Age': [10, 20, 30]}
# 데이터 프레임 생성
df = pd.DataFrame(d)
# 맨 위 2개의 행 확인(default: 5개)
df.head(2)
# 하위 5개의 행 확인
# df.tail()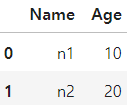
- 불러오기
df = pd.read_csv(path)
데이터 프레임 정보 보기
- 열: `df.columns`
- 열 자료형: `df.dtypes`
- 열 자료형, 값 개수: `df.info()`
- 기초통계정보: `df.describe()`
정렬
`df.sort_values(by='정렬 대상')`
- ascending=True: 오름차순 정렬(기본값)
- ascending=False: 내림차순 정렬
기본 집계
- 고유값 확인: `df['컬럼 이름'].unique()`
- 고유값과 개수 확인: ` df['컬럼 이름'] .value_counts()`
데이터 프레임 조회
- `loc`
# 나이가 10보다 많고 30보다 적은 행 조회
# and-> &, or-> |
df.loc[(df['Age'] > 10) & (df['Age'] < 30)]
# 나이가 10보다 많고 30보다 적은 이름 조회
df.loc[(df['Age'] > 10) & (df['Age'] < 30), ['Name']]
- `isin`
# 나이가 10, 20인 행 조회
df.loc[df['Age'].isin([10, 20])]
- `between`
# 10~20살까지의 행 조회
df.loc[df['Age'].between(10, 20)]
데이터 프레임 집계
- `groupby()`: 특정 기준으로 그룹화
# column_name으로 그룹화하여 target의 합계 구하기
df.groupby('column_name')['target'].sum()
# 'Category'와 'Subcategory'로 그룹화하여 Value의 합계 구하기
grouped = df.groupby(['Category', 'Subcategory'])['Value'].sum()
# # column_name으로 그룹화하여 target의 최소, 최대, 평균값 계산
df.groupby('column_name')['target'].agg(['min', 'max', 'mean'])
- `as_index=True (기본값)`: 그룹 키가 결과의 인덱스로 사용
- `as_index=False`: 그룹 키가 인덱스가 아니라 데이터프레임의 일반 열로 유지
반응형
'KT 에이블스쿨(6기, AI)' 카테고리의 다른 글
| [KT 에이블스쿨(6기, AI)] 4주차, 1차 미니 프로젝트 (0) | 2024.09.25 |
|---|---|
| [KT 에이블스쿨(6기, AI)] 3주차, 웹 크롤링 (0) | 2024.09.24 |
| [KT 에이블스쿨(6기, AI)] 2주차, 데이터 분석(이변량 분석) (0) | 2024.09.23 |
| [KT 에이블스쿨(6기, AI)] 2주차, 데이터 처리(데이터 프레임 조작, 단변량 분석) (0) | 2024.09.23 |
| [KT 에이블스쿨(6기, AI)] 최종 합격 후기 (10) | 2024.09.21 |