
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 알고리즘
- KT 에이블스쿨
- 앙상블
- 백준 사탕 게임
- KT AIVLE
- 케이티 에이블스쿨
- 머신러닝
- 케이티 에이블스쿨 기자단
- kt 에이블스쿨 6기 빅프로젝트
- 케이티 에이블스쿨 6기 spring
- 네트워크
- 티스토리챌린지
- kt 에이블스쿨 6기
- 파이썬
- 백준
- 오블완
- kt 에이블스쿨 6기 ai
- 프로그래머스
- 구현
- 판다스
- 케이티 에이블스쿨 6기 ai
- kt aivle school
- 데이터 프레임
- 케이티 에이블스쿨 6기 후기
- 에이블 기자단
- SQLD
- 케이티 에이블스쿨 6기 java
- kt 에이블스쿨 6기 미니 프로젝트
- kt 에이블스쿨 기자단
- 케이티 에이블스쿨 6기
Archives
- Today
- Total
미식가의 개발 일기
[KT 에이블스쿨(6기, AI)] 3주차, 웹 크롤링 본문
< 3주차 후기>
3주차는 웹크롤링에 대해 학습했습니다!
- 웹크롤링을 하는 방법 뿐만 아니라 웹이 돌아가는 전체 구조를 함께 설명해주셔서 웹크롤링 동작 과정을 더 잘 이해할 수 있었던 거 같습니다.
- 여러가지 방식으로 크롤링을 진행 했는데 Scrapy 방식은 특정 규칙이 정해져 있는 프레임워크이다 보니 다른 방식보다 조금 더 복잡하고 어려웠던 거 같아요. 😅 그래도 실무에서는 거의 Scrapy로 크롤링을 진행한다고 하니 숙지해두면 좋을 거 같습니다!
- 혼자서는 여러가지 시행착오를 겪어야만 알 수 있는 정보들을 미리 시행착오를 겪으시고 어떻게 해야 에러없이 접근할 수 있는지 알려주신 것이 많은 도움이 됐습니다. 😊
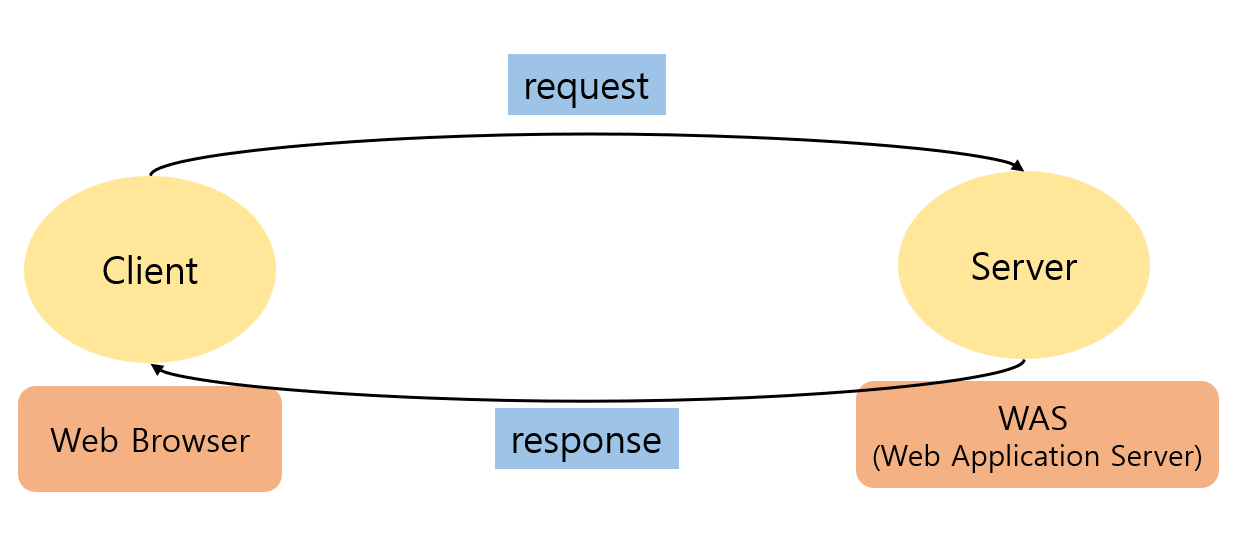
웹 요청-응답 과정
- 아래 그림은 강사님께서 교육 내내 강조하셨던 웹 요청-응답 과정입니다! 이 그림 덕분에 웹 동작 과정을 한눈에 이해할 수 있었어요.
- 클라이언트가 웹 브라우저에서 특정 URL을 클릭하면 웹 브라우저가 HTTP요청을 생성하여 웹 서버를 통해 WAS로 전달합니다.
- 클라이언트의 요청을 받은 WAS는 내부적으로 로직을 처리한 후 응답 데이터를 생성하여 클라이언트에게 전달합니다.
- 웹 브라우저는 받은 응답을 해석하여 사용자가 볼 수 있는 형태로 화면에 표시합니다.
URL 구성요소
※ 예시 URL
https://www.example.com:443/folder/page.html?id=123&search=abc#section1
- 프로토콜: `http://`, `https://` → 리소스에 접근하는 방식, https는 암호화된 데이터를 주고받는다.
- 호스트: `www.example.com` → 도메인 + 서브 도메인
- 도메인: `example.com` → 특정 웹사이트나 서버의 이름
- 포트: `:80` http → 기본 포트, `:443` → https 기본 포트
- 경로: `/folder/page.html` → 서버 내의 특정 리소스(파일 경로, 디렉토리)
- 쿼리 문자열: `?id=123&search=abc` → 서버에 전달되는 추가 정보
- 프레그먼트: `#section1` → 페이지 내에 특정 위치로 이동하기 위한 참조
쿠키 vs 세션 vs 캐시
- 쿠키 -> Client의 Browser에 저장하는 문자열 데이터(로그인 정보, 팝업 다시보지 않음 등), SSD 사용
- 세션 -> Client의 Browser와 Server의 연결 정보(자동 로그인)
- 캐시 -> Client, Server의 RAM(메모리, 입출력 빠름)에 저장하는 데이터
스크래핑 vs 크롤링
- 스크래핑: 특정 페이지의 특정 데이터를 수집
- 크롤링: 여러 페이지를 이동하며 데이터를 수집
웹 크롤링
수집 과정
1. URL 찾기(Chrome Devtool)
2. request → response(data: html(정적 페이지), json(동적 페이지))
3. data → DataFrame으로 파싱
- 동적 페이지: json → list, dict → df parsing
- 정적 페이지: html → bs4, BeautifulSoup(css-selector 사용) → df parsing (※실제 데이터와 개발자 도구에서 제공해주는 데이터 실제 데이터가 다를 수 있으므로 css-selector 수집 후 수정이 필요하다.)
Selenium
- 브라우저 자동화 도구를 제공하는 라이브러리
- 동적 웹 페이지에서 JavaScript에 의해 생성된 콘텐츠를 수집해야 할 경우 유용
- 필요한 구조나 규칙 X → 개발자가 원하는 대로 테스트를 설계하고 구성
Scrapy
- 웹 크롤링 프레임워크
- 실무에서는 거의 Scrapy를 사용
- 정적 웹 페이지에서 대량의 데이터를 수집할 때 유용
- 필요한 정보만 입력하면 크롤링 코드가 만들어지도록 구성(스크래핑을 위한 크롤러와 파서 기능 내장)
- 특정 규칙과 구조를 따라야 함
반응형
'KT 에이블스쿨(6기, AI)' 카테고리의 다른 글
| [KT 에이블스쿨(6기, AI)] 4주차, 머신러닝(머신러닝 이해, 성능 평가) (1) | 2024.09.28 |
|---|---|
| [KT 에이블스쿨(6기, AI)] 4주차, 1차 미니 프로젝트 (0) | 2024.09.25 |
| [KT 에이블스쿨(6기, AI)] 2주차, 데이터 분석(이변량 분석) (0) | 2024.09.23 |
| [KT 에이블스쿨(6기, AI)] 2주차, 데이터 처리(데이터 프레임 조작, 단변량 분석) (0) | 2024.09.23 |
| [KT 에이블스쿨(6기, AI)] 1주차, 파이썬 기초와 Numpy & Pandas (4) | 2024.09.22 |