
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- 케이티 에이블스쿨 6기 ai
- 티스토리챌린지
- kt 에이블스쿨 6기 미니 프로젝트
- 데이터 프레임
- 케이티 에이블스쿨 6기
- KT AIVLE
- 케이티 에이블스쿨 6기 후기
- 백준
- 프로그래머스
- kt 에이블스쿨 6기 ai
- 케이티 에이블스쿨 기자단
- KT 에이블스쿨
- 케이티 에이블스쿨 6기 java
- kt 에이블스쿨 기자단
- kt 에이블스쿨 6기
- 판다스
- 파이썬
- kt 에이블스쿨 6기 빅프로젝트
- 구현
- SQLD
- 에이블 기자단
- ElasticSearch
- 엘라스틱서치
- 앙상블
- kt aivle school
- 알고리즘
- 네트워크
- 오블완
- 머신러닝
- 케이티 에이블스쿨
Archives
- Today
- Total
미식가의 개발 일기
[머신러닝] 다양한 모델이 결합하는 앙상블(보팅, 스태킹, 평균 앙상블, 가중 평균 앙상블) 본문
앙상블이란?
"여러 학습 알고리즘을 결합하여 더 나은 성능을 얻는 머신러닝 기법"
이 중에서도 이 포스팅에서는 다양한 모델을 결합하는 형태를 살펴볼 것이다.
※ 이 포스팅은 구현 위주로 작성되어 있으며 앙상블 개념에 대해 학습하고 싶다면 아래 포스팅을 먼저 읽고 오는 것을 추천한다.
[머신러닝] 앙상블
앙상블이란?"여러 모델의 예측 결과들을 종합해 정확도를 높이는 기법이다"(단 각 모델 간의 상호 연관성이 낮아야 정확도가 높아진다.) 보팅(Voting)동일한 데이터셋에 서로 다른 종류의 모델의
irreplaceablehotgirl.tistory.com
보팅(Voting)
각 모델이 독립적으로 예측을 수행하고 그 결과를 투표에 의해 종합
- estimators: (이름, 모델) 형식의 튜플로 정의
- voting: 하드 보팅은 'hard', 소프트 보팅은 'soft'로 설정
- weight: 가중치, 특정 분류기에 더 높은 가중치를 주고 싶다면 이 파라미터 조정
<데이터 로드와 정제가 완료되었다고 가정>
from sklearn.ensemble import VotingClassifier
rf_model = RandomForestClassifier(n_estimators = 10)
gb_model = GradientBoostingClassifier(n_estimators = 10)
et_model = ExtraTreesClassifier(n_estimators = 10)
# 보팅 분류기
voting_clf = VotingClassifier(estimators=[
('rf', rf_model),
('gb', gb_model),
('et', et_model)],
voting='hard',
weights = [3,2,2])
voting_clf.fit(x_train, y_train)
y_pred = voting_clf.predict(x_test)
스태킹(Stacking)
- estimator: (이름, 모델) 형식의 튜플로 정의
- final_estimator: 메타 모델로 사용할 예측기(기본값: Rogistic Regression)
- cv: 폴드 수, 일반적으로 K-Fold 수행(기본값: 5)
<K-Fold와 관련된 포스팅>
[머신러닝] 교차검증, 하이퍼파라미터 튜닝
교차검증교차검증이란?"데이터를 여러 번 나누어 모델을 반복적으로 훈련하고 평가하는 기법" 교차검증이 필요한 이유는?모델이 너무 복잡하거나 훈련 데이터가 너무 작을 때 모델이 훈련 데
irreplaceablehotgirl.tistory.com
<데이터 로드와 정제가 완료되었다고 가정>
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, ExtraTreesClassifier
from sklearn.ensemble import StackingClassifier
# 기본 학습기 정의
estimators = [
('rf', RandomForestClassifier(n_estimators = 10)),
('gb', GradientBoostingClassifier(n_estimators = 10)),
('et', ExtraTreesClassifier(n_estimators = 10))
]
# 메타 학습기 정의
meta_model = RandomForestClassifier(n_estimators = 10, random_state = 42)
# 스태킹 분류기 정의
stacked_model = StackingClassifier(estimators = estimators,
final_estimator = meta_model,
cv = 3)
stacked_model.fit(X, y)
stack_pred = stacked_model.predict(test)
평균 앙상블(Averaging Ensemble)
여러 모델의 예측 값을 평균내어 최종 예측을 결정
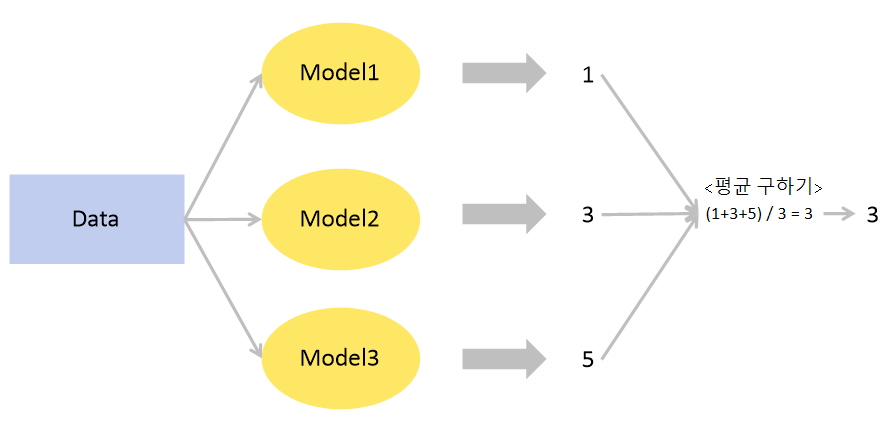
<데이터 로드와 정제가 완료되었다고 가정>
# 모델 정의
rf_model = RandomForestClassifier(n_estimators = 10)
gb_model = GradientBoostingClassifier(n_estimators = 10)
et_model = ExtraTreesClassifier(n_estimators = 10)
# 모델 학습
rf_model.fit(x_train, y_train)
gb_model.fit(x_train, y_train)
et_model.fit(x_train, y_train)
# 각 모델의 예측값 얻기
rf_preds = rf_model.predict(x_valid)
gb_preds = gb_model.predict(x_valid)
et_preds = et_model.predict(x_valid)
# 예측값 평균내기
avg_preds = (rf_preds + gb_preds + et_preds) / 3가중 평균 앙상블(Weighted Averaging Ensemble)
각 모델의 성능에 따라 가중치를 부여한 후 평균내어 최종 예측을 결정
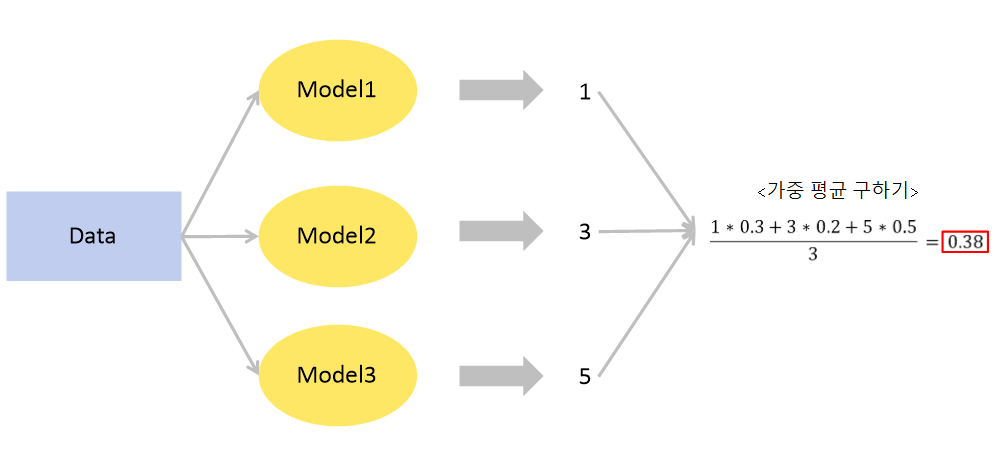
<데이터 로드와 정제가 완료되었고, 모델 정의와 학습은 위에 평균 앙상블과 동일하다고 가정>
# 예측값에 가중치 적용하여 평균내기
weighted_avg_preds = (rf_preds * 0.2 + gb_preds * 0.2 + et_preds * 0.6)
- 최적의 가중치 조합 찾기
# product: 조합 생성
from itertools import product
import numpy as np
# 가중치의 범위
weights_range = np.arange(0.1, 0.9, 0.1)
# 최적 가중치와 점수
best_weight = None
best_score = float('inf')
# 모든 가중치 조합 탐색(조합의 길이: 3)
for weights in product(weights_range, repeat=3):
# 가중치의 합이 1이 되는 조합만 찾기
if sum(weights) != 1:
continue
# 예측값에 가중치 적용 및 RMSE 점수 계산
weighted_predict = (weights[0] * rf_preds + weights[1] * gb_preds + weights[2] * et_preds)
score = mean_squared_error(weighted_predict, y_valid, squared=False)
# 최적의 가중치와 점수 갱신
if score < best_score:
best_weight = weights
best_score = score
- 검증 점수 기반 가중치 조합 찾기
# 각 모델의 검증 점수 계산 (RMSE)
rf_score = mean_squared_error(y_valid, rf_preds, squared = False)
gb_score = mean_squared_error(y_valid, gb_preds, squared = False)
et_score = mean_squared_error(y_valid, et_preds, squared = False)
# 가중치 계산 -> RMSE는 낮을수록 성능이 좋으므로 역수로 계산
rf_weight = 1 / rf_score
gb_weight = 1 / gb_score
et_weight = 1 / et_score
# 가중치 정규화 (총합-> 1)
total_weight = rf_weight + gb_weight + et_weight
rf_weight /= total_weight
gb_weight /= total_weight
et_weight /= total_weight반응형
'ML, DL' 카테고리의 다른 글
| [머신러닝] 앙상블 (3) | 2024.08.29 |
|---|---|
| [머신러닝] 동일 모델을 반복 학습하는 앙상블(부스팅, 시드 앙상블, KFold 앙상블) (0) | 2024.07.31 |
| [머신러닝] predict vs predict_proba (0) | 2024.07.27 |
| [머신러닝] LightGBM과 Gradient Boosting(광고 클릭 예측하기 with 캐글) (1) | 2024.07.27 |
| [머신러닝] 피처 생성과 선택 (0) | 2024.07.25 |