
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 머신러닝
- 앙상블
- kt 에이블스쿨 기자단
- KT AIVLE
- 알고리즘
- SQLD
- 파이썬
- 구현
- kt 에이블스쿨 6기 빅프로젝트
- 데이터 프레임
- 케이티 에이블스쿨 6기 java
- 케이티 에이블스쿨 기자단
- 케이티 에이블스쿨
- 티스토리챌린지
- kt 에이블스쿨 6기 미니 프로젝트
- ElasticSearch
- kt 에이블스쿨 6기
- 케이티 에이블스쿨 6기
- 프로그래머스
- 판다스
- 백준
- 케이티 에이블스쿨 6기 ai
- 에이블 기자단
- 네트워크
- 케이티 에이블스쿨 6기 후기
- KT 에이블스쿨
- 오블완
- kt aivle school
- 엘라스틱서치
- kt 에이블스쿨 6기 ai
Archives
- Today
- Total
미식가의 개발 일기
MLOps: 머신러닝과 DevOps의 만남 본문
최근 데이터 기반 의사결정이 중요해지면서 머신러닝(ML) 모델을 서비스에 적용하는 사례가 점점 늘어나고 있습니다. 하지만 모델을 단순히 학습시키는 것만으로는 실무에서 사용할 수 없습니다.
개발, 배포, 모니터링, 유지보수까지 고려해야 하죠.
이때 필요한 개념이 바로 MLOps(Machine Learning Operations) 입니다.
💡 MLOps란?
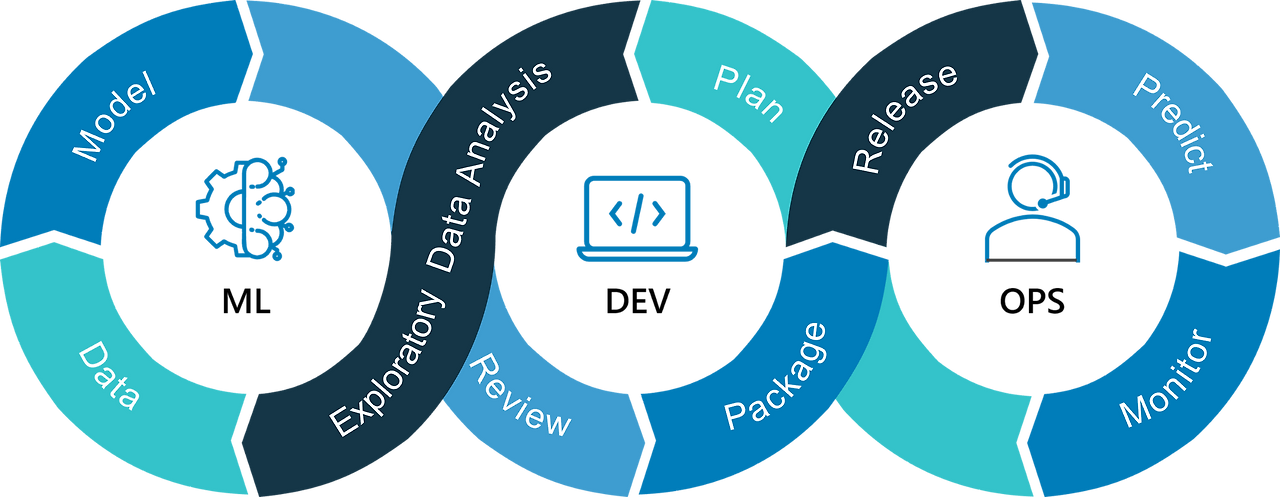
Machine Learning과 DevOps(Development + Operations)의 합성어로,
머신러닝 모델의 개발부터 운영까지 전체 생명주기를 자동화하고, 재현 가능하게 하는 방법론이다.
💡 MLOps의 구성 요소
📖 머신러닝
머신러닝은 어디에 쓰일까?
→ 추천 시스템, 컴퓨터 비전, 자연어 처리, 음성 처리, 이상 탐지
<모델 개발과 관련된 모든 활동>
- 모델 학습 및 최적화: 데이터에 맞는 알고리즘을 선택하고 모델을 학습(실험을 통해 최적의 모델 선택)
- 모델 버전 관리: 여러 실험을 통해 나온 다양한 모델들을 효과적으로 관리 및 버전 관리
- 모델 성능 평가 및 검증: 모델의 정확성, 정밀도, 재현율 등의 성능을 다양한 평가 지표를 사용해 확인하고, 실험을 반복하여 성능을 개선
📖 데이터 엔지니어링
<모델 학습에 적합한 데이터를 수집, 정제, 변환, 저장하는 과정>
- 데이터 파이프라인 구축: 데이터를 실시간 또는 배치 처리 방식으로 수집하고 처리할 수 있는 자동화된 파이프라인 구축
- 데이터 버전 관리: 데이터를 주기적으로 갱신하고 버전 관리하여 데이터의 변경사항을 추적하고, 모델 학습에 사용하는 데이터를 재현 가능하도록 함
- 데이터 품질 관리: 데이터가 정확하고 일관성 있게 유지되도록 품질을 점검하고, 오류가 발생하지 않도록 관리
- 데이터 저장소: 대량의 데이터를 효과적으로 저장하고 관리할 수 있는 시스템을 구축
📖 DevOps
<모델 배포, 운영, 모니터링을 자동화하고 최적화>
- CI/CD 파이프라인 구축: 머신러닝 모델과 데이터를 자동으로 빌드, 테스트, 배포할 수 있도록 파이프라인을 설정
- 모델 배포 자동화: 모델을 API 형태로 배포하거나, 특정 환경에서 모델을 실행할 수 있도록 자동화된 배포 환경을 구축
- 모델 모니터링 및 유지보수: 배포된 모델의 성능을 지속적으로 모니터링하고, 문제가 발생할 경우 자동으로 수정하거나 재학습하는 시스템을 구축
- 자동화된 스케일링: 모델의 부하에 따라 서버 자원을 자동으로 조정할 수 있는 환경을 구축하여, 대규모 데이터를 처리할 수 있도록 함
💡 MLOps의 과정
1️⃣ 데이터 준비 (Data Preparation)
- 데이터 수집
- 데이터 정제: 결측치 처리, 이상치 제거, 데이터 형식 변환 등
- 데이터 탐색 및 분석: 데이터를 분석하고, 모델에 사용할 유용한 피쳐(feature)를 선택
도구
| `Apache Airflow` | 데이터 파이프라인을 관리하고 자동화 |
| `Pandas`, `NumPy` | 데이터 처리 및 분석 |
| `DVC (Data Version Control)` | 데이터 버전 관리 |
| `Apache Kafka` | 실시간 데이터 스트리밍 처리 |
2️⃣ 모델 개발 (Model Development)
- 모델 학습: 학습 알고리즘을 적용하여 모델을 훈련
- 하이퍼파라미터 튜닝: 최적의 모델 성능을 위해 하이퍼파라미터를 조정
- 모델 평가: 정확도, 정밀도, 재현율 등으로 모델 성능 평가
도구
| `MLflow` | 실험 관리, 모델 버전 관리, 하이퍼파라미터 최적화 |
| `TensorFlow`, `PyTorch`, `Scikit-learn` | 모델 학습 및 훈련 |
3️⃣ 모델 배포 (Model Deployment)
- 모델 배포: 모델을 웹 서비스나 애플리케이션에 통합하여 실시간으로 사용할 수 있게 함
- API 제공: 모델을 REST API 형태로 배포하여 다른 시스템에서 쉽게 호출할 수 있게 함
- 스케일링: 모델의 부하에 맞춰 배포된 인프라를 확장하거나 축소
도구
| `Docker`, `Kubernetes` | 컨테이너화된 모델을 배포하고 스케일링 |
| `FastAPI`, `Flask ` | 모델을 API 형태로 배포 |
4️⃣ 모델 모니터링 및 관리 (Model Monitoring and Management)
- 모델 성능 모니터링: 모델이 실제 환경에서 제대로 작동하는지 지속적으로 점검
- 데이터 드리프트 감지: 모델이 과거의 데이터를 기반으로 학습했으므로, 새로운 데이터와의 차이를 감지하고 모델을 재학습시킬 필요가 있음
- 로그 관리 및 알림: 모델 예측에 이상이 생기면 이를 알리고, 필요한 조치를 취함
도구
| `MLflow` | 모델 실험 관리, 버전 관리, 간단한 배포까지 가능 |
| `Seldon Core` | Kubernetes 기반 대규모 모델 서빙, 실시간 추론 API 제공 |
| `Prometheus` | 모델/서비스의 메트릭(성능지표) 수집 |
| `Grafana` | 메트릭 시각화 대시보드 구성 |
| `ELK Stack` | 로그 수집 및 분석, 에러 원인 추적 |
| `Datadog` | 서비스/서버/모델 통합 성능 모니터링 및 알림 설정 |
5️⃣ 모델 재학습 및 업데이트 (Model Retraining and Updating)
- 모델 재학습: 모델의 성능이 떨어졌을 때, 새로운 데이터를 학습시켜 모델을 업데이트
- 모델 버전 관리: 최신 모델을 추적하고, 이전 버전과 비교하며 필요에 따라 롤백
도구
| `Kubeflow` | 전체 ML 파이프라인의 자동화 및 오케스트레이션, 학습/배포 단계 관리 |
| `MLflow` | 모델 실험 추적, 버전 관리, 재학습 관리 |
| `Airflow` | 재학습 스케줄링, 데이터 전처리 등 워크플로 자동화에 사용 |
| `TensorFlow Extended (TFX)` | TensorFlow 기반의 모델 학습부터 배포까지의 파이프라인 자동화 도구 |
반응형
'ML, DL' 카테고리의 다른 글
| 멀티모달 (0) | 2025.05.07 |
|---|---|
| NLP, Transformer, LLM - 자연어 처리부터 대형 언어 모델까지 (1) | 2025.05.05 |
| 얼굴 인식을 위한 딥러닝 모델: YOLO vs YOLO-CLS (0) | 2024.11.02 |
| [머신러닝] 클래스 불균형을 해결하기 위한 샘플링(언더 샘플링, 오버 샘플링) (1) | 2024.10.04 |
| [머신러닝] 앙상블 (3) | 2024.08.29 |