
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 에이블 기자단
- 케이티 에이블스쿨 6기 java
- kt 에이블스쿨 6기 빅프로젝트
- 데이터 프레임
- 티스토리챌린지
- 프로그래머스
- 네트워크
- 머신러닝
- 알고리즘
- kt aivle school
- 백준 사탕 게임
- 오블완
- KT AIVLE
- kt 에이블스쿨 6기
- 케이티 에이블스쿨 6기 후기
- kt 에이블스쿨 6기 미니 프로젝트
- 케이티 에이블스쿨 기자단
- 케이티 에이블스쿨 6기
- kt 에이블스쿨 6기 ai
- 백준
- 케이티 에이블스쿨 6기 spring
- kt 에이블스쿨 기자단
- KT 에이블스쿨
- 앙상블
- 판다스
- 파이썬
- 구현
- 케이티 에이블스쿨 6기 ai
- 케이티 에이블스쿨
- SQLD
- Today
- Total
미식가의 개발 일기
[KT 에이블스쿨(6기, AI)] 5주차, 머신러닝(지도학습 알고리즘, K-분할 교차 검증, 하이퍼파라미터 튜닝) 본문
[KT 에이블스쿨(6기, AI)] 5주차, 머신러닝(지도학습 알고리즘, K-분할 교차 검증, 하이퍼파라미터 튜닝)
대체불가 핫걸 2024. 10. 4. 17:08
<5주차 후기>
- 저번 주차에 이어 머신러닝 수업을 마무리했습니다!
- 지도학습의 기본 알고리즘에 대해 먼저 학습하고, 데이터를 여러 조각으로 나눠 더 좋은 성능을 찾는 K-분할 교차 검증, 모델 성능을 최적화하기 위한 하이퍼파라미터 최적화와 여러 개의 모델을 결합하여 훨씬 강력한 모델을 생성하는 앙상블 알고리즘에 대해 배웠어요. 😊
- 모델을 선정하는 데 있어 가장 먼저 확인해야 할 것은 target 값을 보고 이 문제가 회귀 문제인지 분류 문제인지 구분하는 것입니다. 문제의 특성에 따라 적절한 알고리즘을 선택하는 것이 중요하기 때문에 이 부분 거듭 강조!! 해주셨습니다.
- 하이퍼파라미터 조정이 성능에 큰 영향을 미치는 알고리즘들(K-Nearest Neighbor, Decision Tree 등)은 Grid Search, Random Search를 활용하여 최적의 파라미터를 찾을 수 있고 이는 모델 성능 향상과 관련이 있기 때문에 꼭 확인해 주는 것이 좋습니다. 또, 하이퍼파라미터 튜닝 도구인 GridSearchCV와 RandomizedSearchCV에서는 cv 매개변수를 통해 K-분할 교차 검증이 자동으로 포함되므로 따로 교차 검증을 구현하지 않아도 됩니다!
- XGBoost와 LightGBM은 sklearn에 없는 라이브러리라 따로 설치가 필요하고, target 값도 sklearn에서는 타입 상관없이 사용할 수 있지만 이 2가지 알고리즘은 외부 라이브러리를 쓰기 때문에 정수형 레이블로 변환이 필요합니다.
- 이번 주는 새로운 알고리즘을 많이 배우고 사용해 보는 시간을 가졌는데 이론만으로는 와닿지 않던 개념이 많은 예제 문제를 풀어보며 자연스레 이해가 된 것 같습니다.
- 오늘 배운 내용을 잘 정리해서 다음 주에 있는 두 번째 미니 프로젝트도 잘 마무리하고 싶습니다! 😎
기본 알고리즘
| Linear Regression [선형 회귀] |
K-Nearest Neighbor [K-최근접 이웃 알고리즘] |
Decision Tree [결정 트리] |
Logistic Regression [로지스틱 회귀] |
| 회귀 | 회귀, 분류 | 회귀, 분류 | 분류 |
Linear Regression(선형 회귀)
오차 합이 최소가 되는 회귀식을 찾아 새로운 입력값에 대한 예측을 수행하는 모델

- 편향: `model.intercept_`
- 가중치: `model.coef_`
분류
| 단순 회귀 | 독립변수 하나가 종속변수 하나에 영향을 미치는 선형 회귀 |
| 다중 회귀 | 독립변수 여러 개가 종속변수 하나에 영향을 미치는 선형 회귀 |
모델 선언
from sklearn.linear_model import LinearRegression
model = LinearRegression()
K-Nearest Neighbor(K-최근접 이웃)
가장 가까운 K개의 이웃(neighbors)을 찾아 그 이웃들의 특성에 따라 결과를 예측
※ K값이 적으면 복잡해지고 K값이 크면 단순해진다.(전체 평균에 가까워진다.)
※ 적당한 k값을 찾는 것이 중요 (기본값 5)
- 회귀, 분류에 모두 사용
- 회귀 -> 가장 가까운 k개의 평균
- 분류 -> 가장 가까운 k개의 빈도(다수결)
거리 구하기
- 유클리드 거리

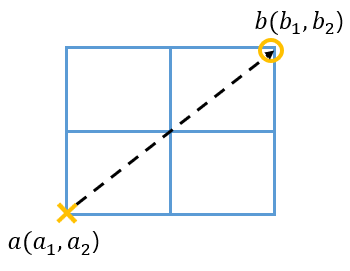
- 맨하튼 거리


→ 맨하튼 거리는 유클리드 거리보다 항상 크거나 같다.
☆ Scaling
Scaling 여부에 따라 KNN 모델 성능이 달라진다.
1. 정규화(Normalization): 0~1 사이의 값으로 조정

from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
# x_train = scaler.fit_transform(x_train) -> fit + transform
x_test = scaler.transform(x_test)
2. 표준화(Standardization): 평균 0 표준편차 1로 조정
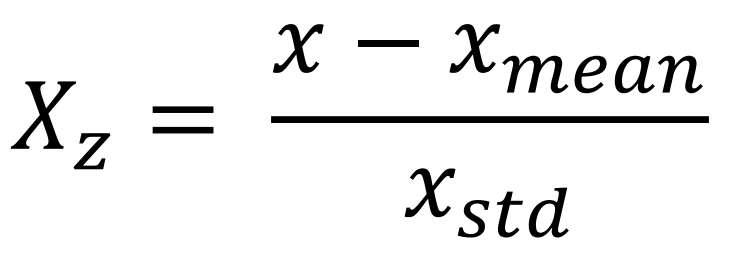
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)모델 선언
from sklearn.neighbors import KNeighborsRegressor # 회귀
from sklearn.neighbors import KNeighborsClassifier # 분류
# n_neighbors: K의 개수 설정(기본값=5)
model = KNeighborsRegressor(n_neighbors=3)
model = KNeighborsClassifier()Decision Tree(결정 트리)
특정 변수의 규칙을 나무 가지가 뻗는 형태로 분류
※ 의미있는 질문을 하는 것이 중요
※ 가지치기(과적합 방지를 위해 트리 깊이 제한하는 튜닝) 필요
- 회귀, 분류에 모두 사용
- 회귀 -> 마지막 노드의 샘플 평균값이 예측값, 비용함수가 MSE
- 분류 -> 마지막 노드의 샘플 최빈값이 예측값, 비용함수가 불순도
※ 불순도, 엔트로피: 낮을수록 완벽하게 분리됐음을 의미
- 정보 이득: 부모 엔트로피와 자식 엔트로피의 차이, 정보 이득 값이 클수록 많은 정보를 제공
- 변수 중요도 확인: `model.feature_importances_`
가지치기
- 과적합 방지를 위해 필요
- 하이퍼파라미터 값 조정
| 파라미터 | 설명 |
| max_depth | 트리의 최대 깊이(기본값: None) |
| min_samples_split | 노드 분할을 위한 최소 샘플 수(기본값: 2) |
| min_samples_leaf | 리프(종료) 노드가 되기 위한 최소 샘플 수(기본값: 1) |
| max_feature | 최선의 분할을 위한 feature 수(기본값: 1) |
| max_leaf_node | 리프 노드 최대 개수 |
모델 선언
from sklearn.tree import DecisionTreeRegressor # 회귀
from sklearn.tree import DecisionTreeClassifier # 분류
# 괄호 안에 파라미터 값 조정
model = DecisionTreeRegressor(max_depth=5)
model = DecisionTreeClassifier()
트리 시각화
- Graphviz 활용
※ 다운로드 후 사용
Graphviz
Please join the Graphviz forum to ask questions and discuss Graphviz. What is Graphviz? Graphviz is open source graph visualization software. Graph visualization is a way of representing structural information as diagrams of abstract graphs and networks. I
graphviz.org
from sklearn.tree import export_graphviz
from IPython.display import Image
export_graphviz(model, # 모델 이름
out_file='tree.dot', # 파일 이름
feature_names=list(x), # Feature 이름
class_names=['class1', 'class2'], # Target Class 이름
rounded=True, # 둥근 테두리
precision=2, # 불순도 소숫점 자리수
max_depth=3, # 시각화할 트리 깊이
filled=True) # 박스 내부 채우기
# 파일 변환
!dot tree.dot -Tpng -otree.png -Gdpi=300
# 이미지 파일 표시
Image(filename='tree.png')Logistic Regression(로지스틱 회귀)
주어진 특성(Feature) 값을 기반으로 0 또는 1의 범주로 분류
함수
이진 분류
- 시그모이드 함수 또는 로지스틱 함수

- 0.5를 임계값으로 하여 이보다 크면 1, 작으면 0으로 분류
- 선형 판별식 f(x)값이 커지면 1, 작아지면 0에 가까워짐(f(x) → ∞: 1, f(x) → -∞: 0, f(x) → 0: 0.5)
다중 분류
- 소프트맥스 함수

모델 선언
from sklearn.linear_model import LogisticRegression
# max_iter: 최대 반복 횟수 지정, 기본값 100(500으로 설정해주지 않으면 에러 발생)
model = LogisticRegression(max_iter=500)※ linear_model에서 불러오지만 분류 문제를 푸는 알고리즘으로 평가 지표를 불러올 때 주의해야 함(confusion_matrix, classification_report)
확률값 확인
model.predict_proba(x_test)→ [0일 확률, 1일 확률] 확인 가능
K-분할 교차 검증
- 데이터를 여러 조각으로 나누어 여러 번 테스트해 보는 방법
- 모든 데이터가 평가에 한 번, 학습에 k-1번 사용되고 K개의 분할에 대한 평균 성능이 최종 성능이 됨

# 1. 불러오기
from sklearn. # 알고리즘 라이브러리 호출
from sklearn.model_selection import cross_val_score
# 2. 선언하기
model = # 모델 선언
# 3. 검증하기
cv_score = cross_val_score(model, x_train, y_train, cv=10) # cv: 분할 개수(기본값: 5)
# 4. 확인
print(cv_score)
print(cv_score.mean())
하이퍼파라미터 튜닝
모델 성능을 최적화하기 위해 사용자가 조절하는 매개변수
( KNN 알고리즘의 n_neighbors, Decision Tree 알고리즘의 max_depth 등)
Grid Search
- 모든 파라미터 값을 사용 → 정확도↑ 시간 효율↓
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier()
param = {'n_neighbors': range(1, 100, 10), 'metric': ['m1', 'm2']}
model = GridSearchCV(knn_model, param, cv=3)
Random Search
- 지정된 하이퍼파라미터 범위에서 값을 무작위로 샘플링 → 정확도 보장X, 시간 효율↑
from sklearn.model_selection import RandomizedSearchCV
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier()
param = {'n_neighbors': range(1, 100, 10), 'metric': ['m1', 'm2']}
model = RandomizedSearchCV(knn_model, param, cv=3, n_iter=20) # cv: K-Fold 분할 개수, n_iter: 샘플링 횟수
결과 확인
- 최적의 파라미터로 학습된 모델의 변수 중요도: `model.best_estimator_.feature_importances_`
- 수행 정보: `model.cv_results_`
- 최적 파라미터: `model.best_params_`
- 최고 성능: `model.best_score_`
앙상블 알고리즘
여러 개의 모델을 결합하여 훨씬 강력한 모델을 생성하는 기법
- 모델 생성 후 변수 중요도 확인: `model.feature_importances_`
보깅(Voting)
여러 모델들의 예측 결과를 투표를 통해 최종 예측 결과를 결정
- 하트 보팅: 다수 모델이 예측한 값
- 소프트 보팅: 가장 확률이 높은 값
배깅(Bagging)
- 데이터로부터 부트스트랩 한 데이터로 모델들을 학습시킨 후, 모델들의 예측 결과를 집계
- 같은 유형의 알고리즘 기반 모델들을 사용
※ 부트스트랩 데이터: 반복적으로 샘플을 무작위로 추출하여 새로운 데이터셋을 생성한 것
- 범주형: 다수결 투표
- 연속형: 평균
- Random Forest
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(max_depth=5)
부스팅(Boosting)
- 이전 모델이 제대로 예측하지 못한 오류가 큰 데이터에 가중치를 부여하여 다음 모델이 학습과 예측을 진행
- 같은 유형의 알고리즘 기반 모델들을 사용
- 배깅에 비해 성능이 좋지만, 속도가 느리고 과적합 발생 가능성
※ XGBoost, lightGBM은 sklearn에서 제공되지 않아 설치하는 과정이 필요하고, target 변수도 항상 숫자여야 함
- XGBoost
# xgboost 설치
!pip install xgboostfrom xgboost import XGBClassifier
model = XGBClassifier(max_depth=5, n_estimators=100)
<트리 시각화>
# graphviz 설치
!pip install graphviz
from xgboost import plot_tree
plot_tree(model)
- LightGBM
# lightgbm 설치
!pip install lightgbmfrom lightgbm import LGBMClassifier
# 선언하기
model = LGBMClassifier(max_depth=5, verbose=-1) # verbose=-1: 진행 상황 출력 생략- 변수 중요도 확인
- lgb_model.feature_importances_(importance_type='gain'): 얼마나 많은 정보 이득을 제공했는지
- lgb_model.feature_importances_(importance_type='split'): 얼마나 자주 트리의 노드 분할에 사용되었는지
스태킹(Stacking)
- 여러 모델의 예측 값을 최종 모델의 학습 데이터로 사용하여 예측
- 기본 모델로 4개 이상 선택해야 좋은 결과를 기대할 수 있음
'KT 에이블스쿨(6기, AI)' 카테고리의 다른 글
| [KT 에이블스쿨(6기, AI)] 6주차, 딥러닝(회귀 모델링, 분류 모델링) (0) | 2024.10.12 |
|---|---|
| [KT 에이블스쿨(6기, AI)] 5주차, 2차 미니 프로젝트 (1) | 2024.10.10 |
| [KT 에이블스쿨(6기, AI)] 4주차, 머신러닝(머신러닝 이해, 성능 평가) (1) | 2024.09.28 |
| [KT 에이블스쿨(6기, AI)] 4주차, 1차 미니 프로젝트 (0) | 2024.09.25 |
| [KT 에이블스쿨(6기, AI)] 3주차, 웹 크롤링 (0) | 2024.09.24 |