
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 네트워크
- kt aivle school
- 케이티 에이블스쿨 6기 후기
- 알고리즘
- kt 에이블스쿨 6기
- 머신러닝
- KT 에이블스쿨
- kt 에이블스쿨 6기 빅프로젝트
- 케이티 에이블스쿨 6기 ai
- kt 에이블스쿨 6기 미니 프로젝트
- 앙상블
- 판다스
- 백준
- kt 에이블스쿨 기자단
- SQLD
- KT AIVLE
- kt 에이블스쿨 6기 ai
- 파이썬
- 에이블 기자단
- 케이티 에이블스쿨 기자단
- 구현
- 백준 사탕 게임
- 티스토리챌린지
- 케이티 에이블스쿨 6기 java
- 데이터 프레임
- 케이티 에이블스쿨 6기
- 케이티 에이블스쿨
- 프로그래머스
- 케이티 에이블스쿨 6기 spring
- 오블완
Archives
- Today
- Total
미식가의 개발 일기
[머신러닝] 교차검증, 하이퍼파라미터 튜닝 본문
교차검증
교차검증이란?
"데이터를 여러 번 나누어 모델을 반복적으로 훈련하고 평가하는 기법"
교차검증이 필요한 이유는?
- 모델이 너무 복잡하거나 훈련 데이터가 너무 작을 때 모델이 훈련 데이터에 지나치게 잘 맞춰져 있어 새로운 데이터에 일반화하는 능력이 떨어지게 되는데 이를 오버피팅이라고 한다. 교차검증은 오버피팅을 방지하기 위한 기법이다.
- 과적합을 방지하고, 신뢰성 있는 성능 평가를 제공한다.
K-겹 교차 검증(K-Fold Cross Validation)
- 주어진 데이터셋을 K개의 폴드로 나누고 각 폴드를 한 번씩 검증 데이터로 사용하여 K번 훈련 및 평가를 수행

검증 절차
- 테스트 데이터 분할
- 남은 데이터셋을 K개의 폴드로 나누기(K는 사용자가 설정)
- 모델 훈련 및 검증
- 분할해놓은 테스트 데이터로 최종 모델 성능 평가
구현
- Scikit-Learn 라이브러리에서 제공하는 아이리스(Iris) 데이터셋 사용
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
display(X[:3], y[:3])
KFold 클래스로 구현
import numpy as np
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 모델 생성
model = LogisticRegression()
# KFold 객체 생성
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 교차 검증 점수를 저장할 리스트
scores = []
# K-겹 교차 검증 수행
for train_index, test_index in kf.split(X):
# 훈련 데이터와 테스트 데이터 분리
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 모델 훈련
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 정확도 계산
score = accuracy_score(y_test, y_pred)
scores.append(score)
# 결과 출력
print("교차 검증 점수:", scores)
print("평균 교차 검증 점수:", np.mean(scores))
print("표준 편차:", np.std(scores))
cross_val_score로 구현
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
# 모델 생성
model = LogisticRegression()
# 5-겹 교차 검증 수행
scores = cross_val_score(model, X, y, cv=5)
# 결과 출력
print("교차 검증 점수:", scores)
print("평균 교차 검증 점수:", np.mean(scores))
print("표준 편차:", np.std(scores))
-> cross_val_score는 간편하게 사용할 수 있지만, KFold를 직접 사용하는 경우 더 많은 제어와 설정이 가능하다.
하이퍼파라미터 튜닝
하이퍼파라미터 튜닝이란?
"머신러닝 모델을 학습할 때 설정하는 외부 구성 값의 최적의 조합을 찾는 과정"
사이킷런(Scikit-Learn) 라이브러리에서 제공하는 당뇨병 환자 데이터셋 사용
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split, KFold
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV, cross_val_score
import matplotlib.pyplot as plt
import numpy as np
# 데이터셋 로드
data = load_diabetes()
X = data.data
y = data.target
display(X[:3], y[:3])
학습용 데이터와 테스트용 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Ridge 회귀 모델의 alpha 하이퍼파라미터 튜닝
K-Fold 교차검증 설정 및 Ridge() 회귀 모델 정의
# 5개의 폴드 무작위로 섞기
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# Ridge 회귀 모델 정의
ridge = Ridge()
후보 리스트 alpha_list 정의 후 각 alpha에 대한 교차검증 수행
for alpha in alpha_list:
ridge_model = Ridge(alpha=alpha)
scores = cross_val_score(ridge_model, X_train, y_train, scoring='neg_mean_squared_error', cv=kf)
scores_list.append(np.mean(scores)) # 점수 저장-> 하이퍼파라미터 튜닝으로 8개의 alpha 값을 순회하며 각 alpha마다 5개의 K-Fold 교차검증을 거쳐
평균값을 scores_list에 저장한다.
최적의 alpha값 및 성능 확인
# np.argmax: 배열에서 가장 큰 인덱스 값 반환
optimal_alpha =alpha_list[np.argmax(scores_list)]
best_score = max(scores_list)
print(f"Optimal alpha: {optimal_alpha}")
print(f"Best Score: {best_score}")
결과 시각화
plt.figure(figsize=(10,6))
plt.plot(alpha_list, scores_list)
plt.title('Alpha vs. CV Score')
plt.show()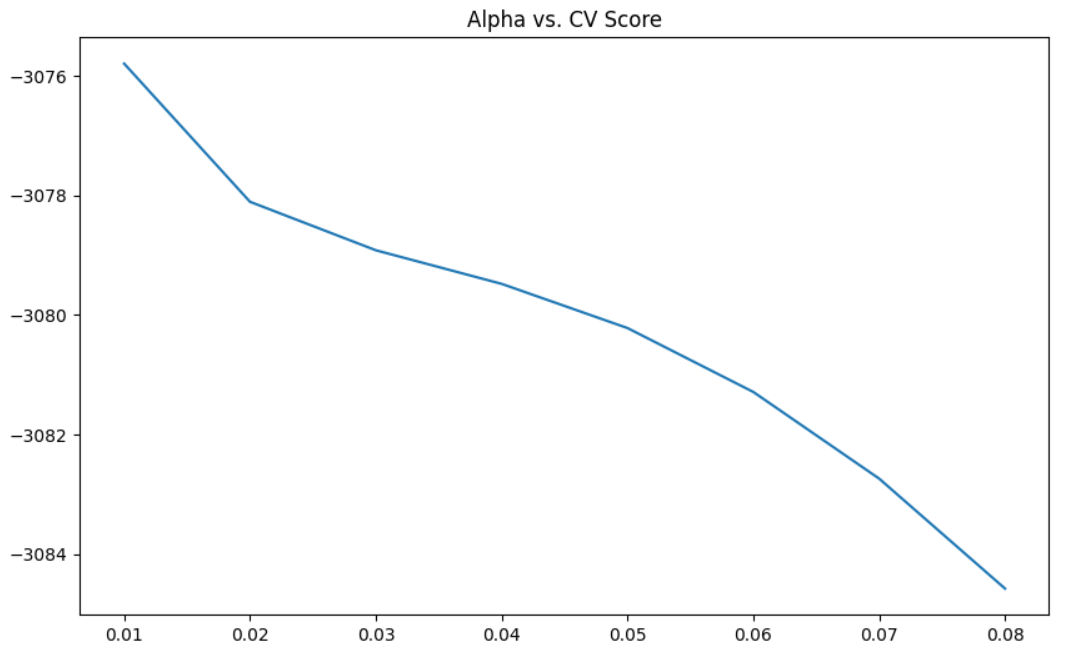
최종 코드
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split, KFold
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV, cross_val_score
import matplotlib.pyplot as plt
import numpy as np
# 데이터셋 로드
data = load_diabetes()
X = data.data
y = data.target
display(X[:3], y[:3])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 5개의 폴드 무작위로 섞기
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# Ridge 회귀 모델 정의
ridge = Ridge()
for alpha in alpha_list:
ridge_model = Ridge(alpha=alpha)
scores = cross_val_score(ridge_model, X_train, y_train, scoring='neg_mean_squared_error', cv=kf)
scores_list.append(np.mean(scores)) # 점수 저장
# np.argmax: 배열에서 가장 큰 인덱스 값 반환
optimal_alpha =alpha_list[np.argmax(scores_list)]
best_score = max(scores_list)
print(f"Optimal alpha: {optimal_alpha}")
print(f"Best Score: {best_score}")
plt.figure(figsize=(10,6))
plt.plot(alpha_list, scores_list)
plt.title('Alpha vs. CV Score')
plt.show()반응형
'ML, DL' 카테고리의 다른 글
| [머신러닝] LightGBM과 Gradient Boosting(광고 클릭 예측하기 with 캐글) (0) | 2024.07.27 |
|---|---|
| [머신러닝] 피처 생성과 선택 (0) | 2024.07.25 |
| [머신러닝] 차원 축소(PCA, LDA) (1) | 2024.07.24 |
| [머신러닝] 데이터 불균형 (0) | 2024.07.23 |
| [머신러닝] 피처 엔지니어링으로 예측 성능 높이기 (1) | 2024.07.23 |