NLP, Transformer, LLM - 자연어 처리부터 대형 언어 모델까지
Chat GPT와 같은 초거대 언어 모델(LLM)이 발전하면서 이제는 일상 속에서 없어서는 안 될 존재가 되어가고 있습니다.
이러한 LLM의 근본에는 바로 ‘Transformer’라는 구조와, 그에 기반한 자연어 처리(NLP) 기술의 진화가 있는데요.
✔ 자연어 처리(NLP)는 어떤 문제를 다루는지,
✔ Transformer는 왜 기존 방식을 뛰어넘었는지,
✔ LLM은 어떤 방식으로 학습되고 활용되는지,
✔ 그리고 최근 주목받고 있는 LoRA 같은 효율적인 파인튜닝 기법까지
하나씩 차근차근 정리해보겠습니다.
1️⃣ NLP란? – 언어를 이해하는 기술
Natural Language Processing의 약자로 자연어, 즉 사람이 쓰는 언어를 컴퓨터가 이해하고 해석할 수 있게 만드는 기술이다.
🔔 대표 NLP 작업들
- 문장 분류 / 감정 분석
- 기계 번역
- 텍스트 요약
- 질의응답 시스템
🔔 N-Gram
- N개의 단어 묶음
- 언어 모델링, 자동 완성, 스팸 필터링 등에 활용
- 예: "I am happy" → 2-gram → "I am", "am happy"
2️⃣ 토큰과 임베딩 – 언어를 숫자로 바꾸는 과정
컴퓨터는 문자를 이해하지 못하므로 NLP는 언어 → 숫자 벡터로 바꾸는 전처리가 필수이다.
🔔 토큰(Token)
문장을 작은 조각으로 나눈 단위
: "나는 밥을 먹었다" → ["나", "는", "밥", "을", "먹", "었", "다"]
✔️ 토큰화 기법
- BPE (Byte Pair Encoding): 자주 등장하는 문자 쌍을 병합
- Byte-Level BPE: 바이트 단위로 쪼개므로 한글, 이모지 등 처리 가능 (GPT 계열에서 사용)
🔔 임베딩(Embedding)
토큰을 의미를 담은 벡터로 변환하는 과정
: "강아지"와 "개"는 유사한 벡터로 매핑
: 비슷한 단어는 가까운 공간에, 관련 없는 단어는 멀어짐(거리 계산)
3️⃣ Stable Diffusion
텍스트를 입력받아 이미지를 생성하는 생성형 AI 모델이다.
- 학습 대상을 먼저 확산시켜놓고, 노이즈 이미지에서 원본을 복원하는 방향으로 학습
- 잠재 공간을 활용해 고차원 이미지를 압축해 효율적인 연산 가능

1. 텍스트 임베딩 (Text Encoding)
사용자가 입력한 문장(Prompt)은 Text Encoder를 통해 벡터(Embedding)로 변환되어 고차원 임베딩 공간으로 매핑된다.
2. 노이즈 이미지 생성
초기 입력은 완전한 노이즈 이미지이며, 이는 이미지 생성의 시작점이다.
3. 디퓨전 프로세스 (Reverse Diffusion)
수백 번의 반복을 통해 노이즈를 점차 제거하면서 이미지로 복원해 나가는 과정이다.
핵심 모델은 U-Net이며, 현재 노이즈 상태와 텍스트 임베딩을 함께 입력받아 점점 더 정제된 이미지를 생성한다.
<U-Net 학습 과정>
- 완전히 섞인 노이즈 상태에서 시작해, 텍스트 의미를 따라 점차 노이즈를 제거하며 이미지를 복원하는 방식이다.

4. Cross-Attention 메커니즘
U-Net 내부에는 Cross-Attention Layer가 포함되어 있어, 텍스트와 이미지 특징을 연결하여 어떤 부분을 어떻게 수정할지 결정한다.
→ 단순한 노이즈 제거가 아닌, 텍스트 의미에 맞춘 이미지 복원을 가능하게 한다.
5. 잠재 이미지 텐서 생성 (Latent Tensor)
노이즈 제거가 반복되면서 생성된 고차원 Feature Map은 VAE(Variational Autoencoder)를 통해 잠재 공간(Latent Space) 형태로 압축된다.
→ 이는 메모리 사용량을 줄이고 연산 효율을 높이기 위한 구조이다.
4️⃣ Transformer – NLP의 패러다임을 바꾼 구조
Transformer는 2017년 논문 "Attention is All You Need"에서 처음 제안된 모델이다.
이전에는 RNN, LSTM을 사용했지만, Transformer는 다음과 같은 장점으로 모든 것을 바꿔놓았다.
🔔 구조 요약
[토큰] → 임베딩 → 위치 정보(Positional Encoding) → Self-Attention → Feed Forward → 출력
🔔 Positional Encoding
각 단어 임베딩에 위치 정보를 더해주는 방식이다.
Transformer는 입력된 단어들을 한 번에 처리하기 때문에, 각 단어가 문장에서 어떤 순서로 나타나는지 알 수 없다. 예를 들어, "나는 밥을 먹었다"와 "밥을 나는 먹었다"는 문장은 단어가 같은데, 순서가 다르기 때문에 의미가 달라진다.
Transformer는 각 단어를 동시에 처리하므로, 순서 정보가 없으면 이런 차이를 구분할 수 없다.
따라서 Positional Encoding을 통해 각 단어 임베딩에 순서 정보를 추가한다. 이를 통해 모델은 단어들 간의 순서를 알 수 있게 되어, 의미의 차이를 이해할 수 있다.
🔔 Self-Attention (Transformer의 핵심!)
Self-Attention은 문장 안의 단어들이 서로 어떤 관계를 맺고 있는지를 계산하는 방식이다.
예를 들어, 문장이 "나는 밥을 먹었다"일 때, "먹었다"는 "밥"과 밀접한 관련이 있다.
이런 단어 간 연관성을 스스로 판단해, 중요한 단어일수록 더 높은 비중을 두게 한다.
즉, 각 단어가 다른 모든 단어를 '주목'하며 문장의 의미를 이해하는 방식이다.
Self-Attention을 계산하기 위해, 입력된 단어 벡터는 세 가지 벡터로 변환된다:
- Q (Query): 현재 단어가 알고 싶은 정보
- K (Key): 다른 단어가 가진 특징
- V (Value): 실제로 전달되는 정보
이 세 벡터를 통해, 현재 단어가 다른 단어들과 얼마나 관련 있는지를 수치로 계산한다.

→ Query와 Key를 내적해 유사도(Attention Score)를 구하고, 이 값을 기반으로 Value들을 가중합해 최종 출력으로 만든다.
🔔 Multi-Head Attention
Self-Attention을 한 번만 수행하는 것이 아니라, 여러 "헤드(head)"를 병렬로 사용해 다양한 의미 관계를 동시에 학습할 수 있다.
이를 Multi-Head Attention이라고 하며, 문맥을 더 풍부하게 이해할 수 있게 한다.
🔔 Feed Forward Network
Self-Attention을 통과한 벡터는 FFN(Feed Forward Network)이라는 작은 신경망을 한 번 더 통과한다.
여기서 Residual Connection(기울기 소실 문제를 피하기 위해 입력값을 출력값에 더함)과 Layer Normalization(정규화)이 함께 적용되어 학습의 안정성과 성능을 높인다.
5️⃣ LLM (Large Language Model)
대규모 언어 모델(LLM)은 자연어 처리(NLP) 분야에서 혁신적인 발전을 이끈 딥러닝 기반의 인공지능 모델이다.
방대한 양의 텍스트 데이터를 학습하여 자연어를 이해하고 생성할 수 있는 능력을 갖춘 LLM은 최근 많은 주목을 받고 있다.
예) GPT, BERT, Claude, LLaMA, Gemini
🔔 LLM의 핵심 특징
1. 대규모 학습
2. 사전 학습과 파인튜닝
- 사전 학습(Pre-training): 모델이 거대한 텍스트 데이터로 일반적인 언어 패턴과 구조를 학습하는 단계이다.
- 파인튜닝(Fine-tuning): 사전 학습된 모델을 특정 작업에 맞게 추가로 학습시키는 단계
3. Transformer 구조
대부분의 LLM은 Transformer 아키텍처를 기반으로 한다. Self-Attention 기법을 사용해 문맥 전체를 고려하여 단어들 간의 상호 관계를 파악하고, 이를 통해 단어의 중요도를 동적으로 계산한다.
4. 비지도 학습(Zero-shot Learning)
LLM은 비지도 학습의 방식을 채택하여 레이블이 없는 데이터를 활용해 학습하고 예측을 수행한다.
6️⃣ 파인튜닝(Fine-Tuning)
1. 전체 파인튜닝 (Full Fine-Tuning)
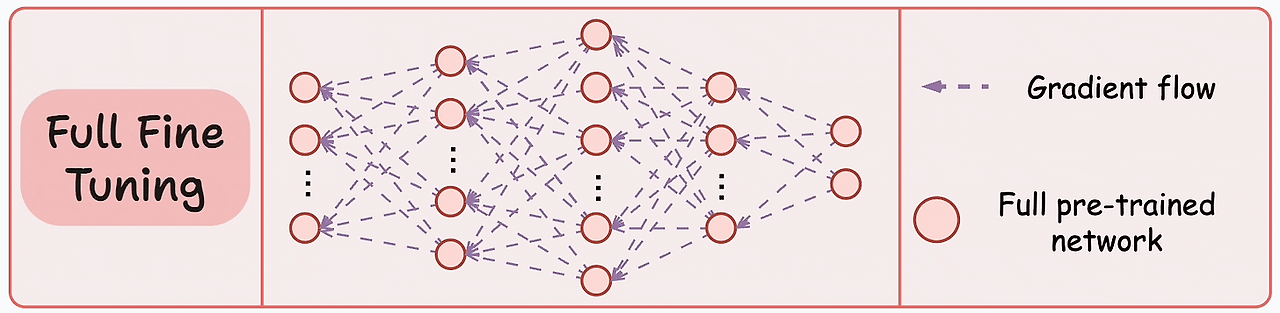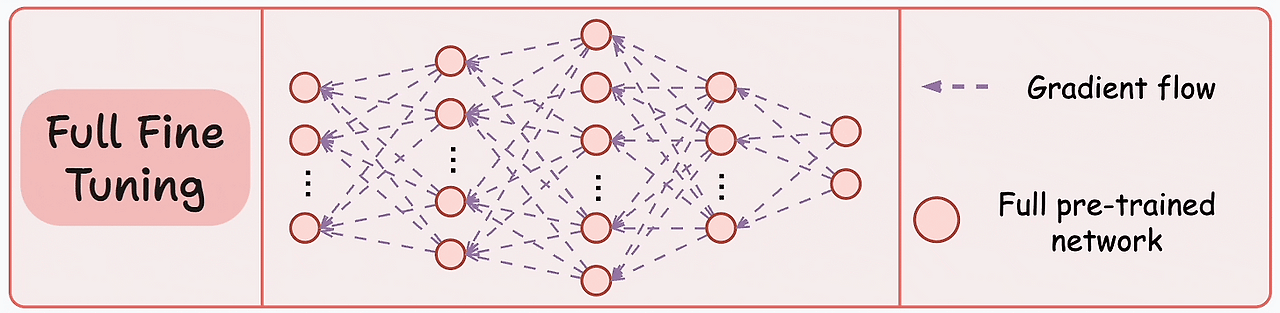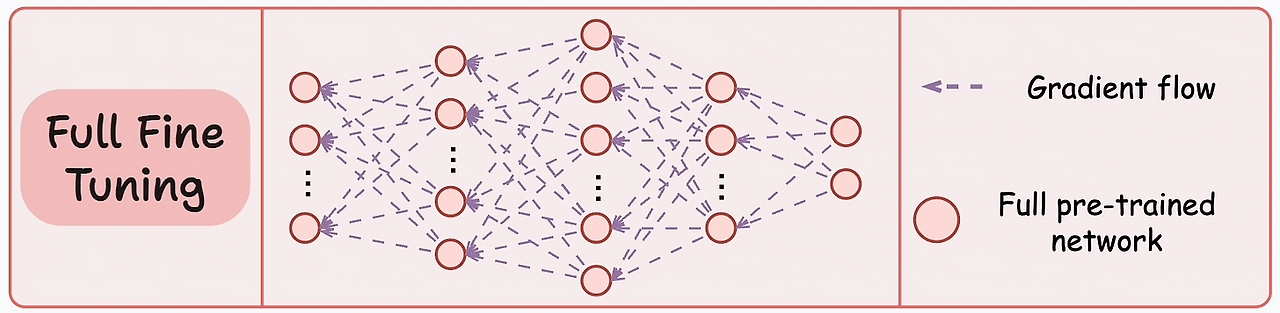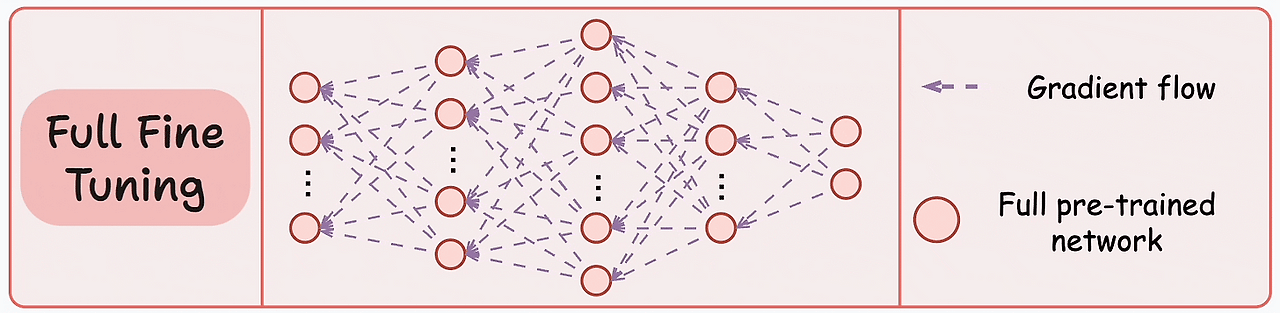
- 모델의 모든 층을 다시 학습
- 모든 파라미터가 업데이트되므로, 최적화가 매우 정밀하지만, 자원 소모가 크고 시간이 오래 걸릴 수 있다.
2. 부분 파인튜닝 (Partial Fine-Tuning)
- 모델의 일부 상위 몇 개 층만 학습시키고, 나머지 층은 고정(freeze)하여 학습하지 않는 방식
- 학습해야 할 파라미터가 적어져, 학습 속도와 효율성이 높아진다.
3. PEFT (Parameter-Efficient Fine-Tuning)
- 일부 파라미터만 학습하도록 설계된 효율적인 파인튜닝 기법
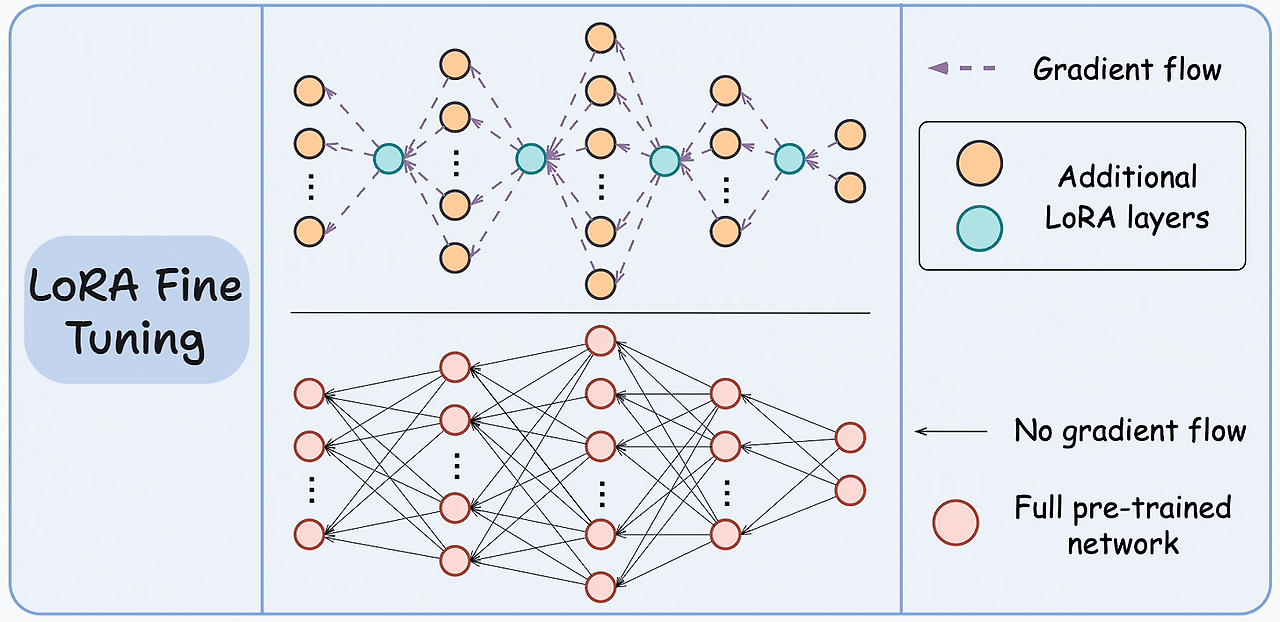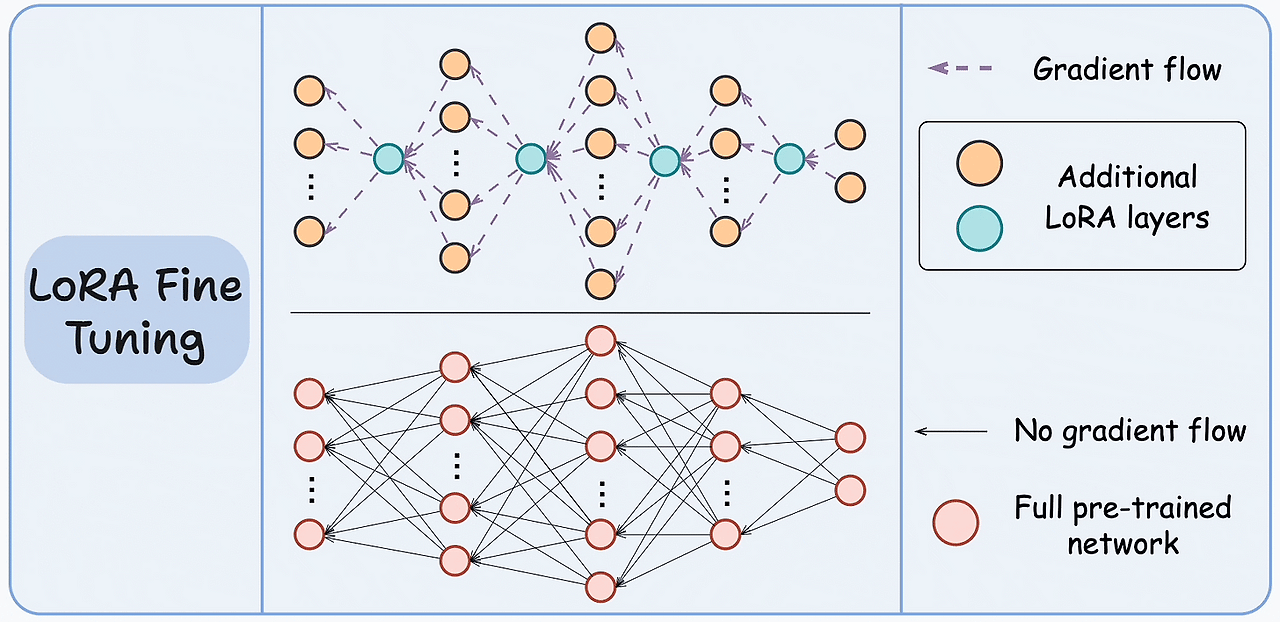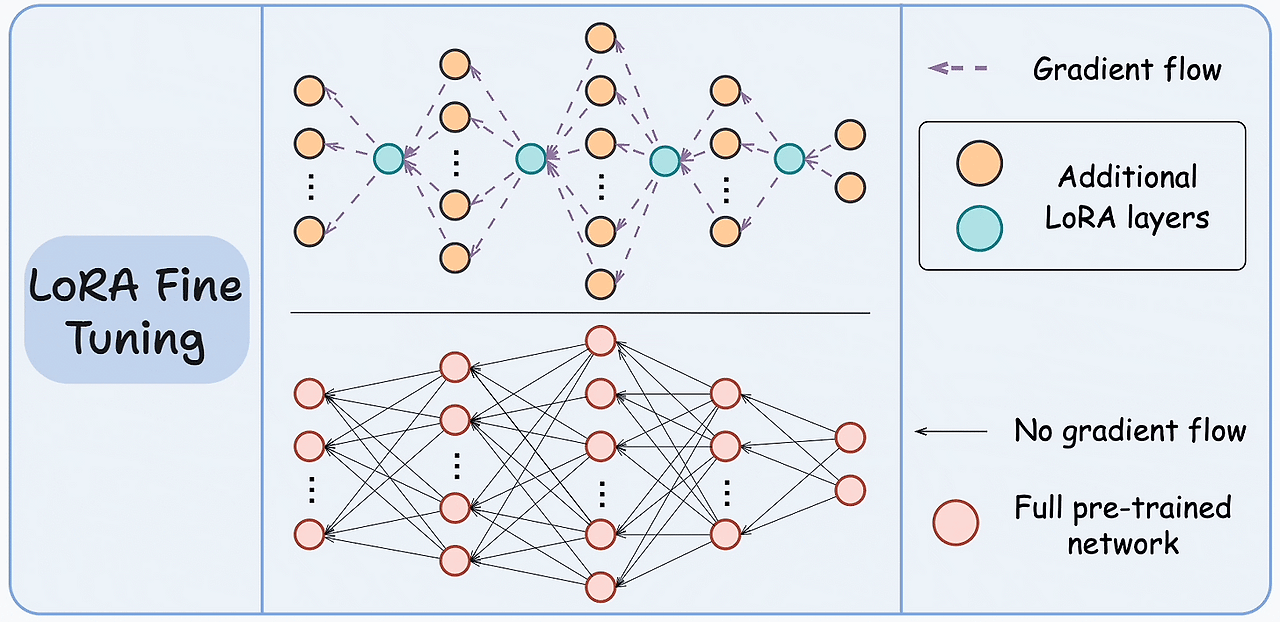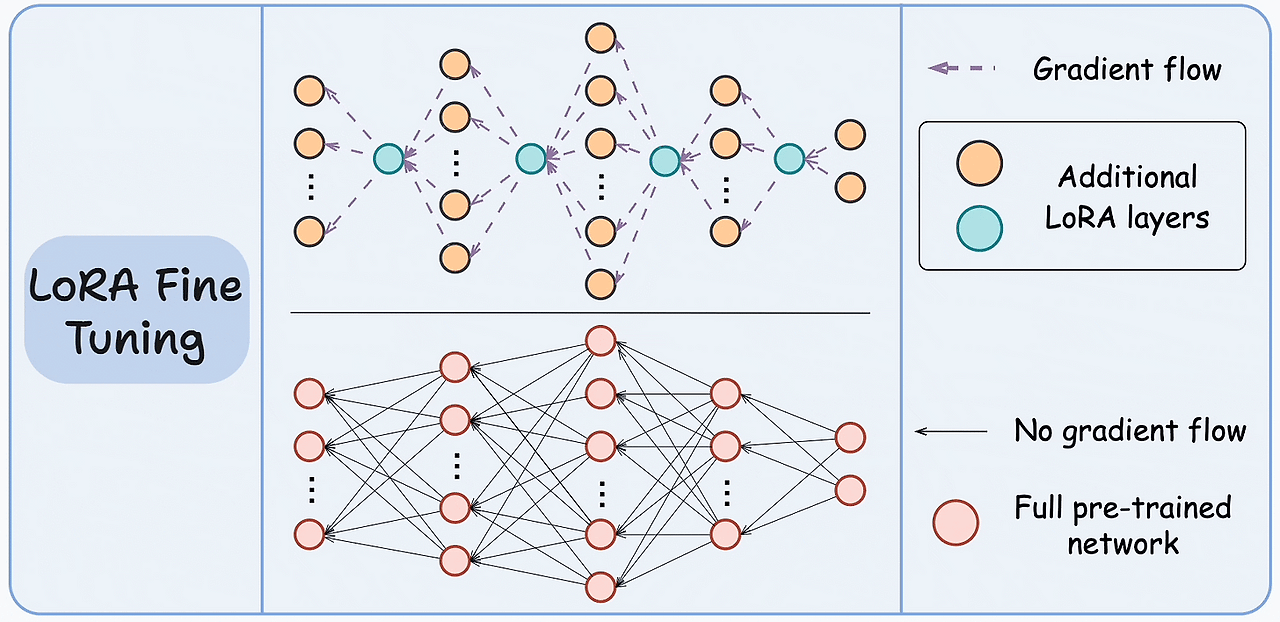
<LoRA>
PEFT의 대표 기법으로 기존 LLM의 성능은 유지하면서 훨씬 적은 파라미터만으로 파인튜닝 할 수 있는 기법
원래 모델의 파라미터를 그대로 두고, 학습 가능한 저차원 행렬을 추가
W' = W + ΔW
ΔW ≈ A × B (A: d×r, B: r×k → r은 작음)
# A, B는 학습 가능한 저차원 행렬이고, r 값이 작기 때문에 학습량, 저장용량이 매우 작아짐